|
Research Ideas and Outcomes :
Research Article
|
|
Corresponding author: Hanjo Hamann (hanjo.hamann@ebs.edu)
Academic editor: Tamara Heck
Received: 05 Jul 2022 | Accepted: 08 Nov 2022 | Published: 22 Nov 2022
© 2022 Rima-Maria Rahal, Hanjo Hamann, Hilmar Brohmer, Florian Pethig
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation:
Rahal R-M, Hamann H, Brohmer H, Pethig F (2022) Sharing the Recipe: Reproducibility and Replicability in Research Across Disciplines. Research Ideas and Outcomes 8: e89980. https://doi.org/10.3897/rio.8.e89980
|
|
Abstract
The open and transparent documentation of scientific processes has been established as a core antecedent of free knowledge. This also holds for generating robust insights in the scope of research projects. To convince academic peers and the public, the research process must be understandable and retraceable (reproducible), and repeatable (replicable) by others, precluding the inclusion of fluke findings into the canon of insights. In this contribution, we outline what reproducibility and replicability (R&R) could mean in the scope of different disciplines and traditions of research and which significance R&R has for generating insights in these fields. We draw on projects conducted in the scope of the Wikimedia "Open Science Fellows Program" (Fellowship Freies Wissen), an interdisciplinary, long-running funding scheme for projects contributing to open research practices. We identify twelve implemented projects from different disciplines which primarily focused on R&R, and multiple additional projects also touching on R&R. From these projects, we identify patterns and synthesize them into a roadmap of how research projects can achieve R&R across different disciplines. We further outline the ground covered by these projects and propose ways forward.
Keywords
reproducibility, replicability, interdisciplinary, open science practices
Introduction
In the quest to gain knowledge and advance scientific discovery, the roles of openness, transparency and free knowledge are increasingly being recognized (
In philosophy of science and research, replicability and reproducibility (R&R) are discussed as central criteria for robust knowledge (
How these general principles of R&R are defined, discussed, and implemented, however, varies widely between different research disciplines and schools of thought (for an overview, see
Challenges for Reproducibility and Replicability across Disciplines
Although R&R are often argued to be important features of research processes to generate robust knowledge, it is not always clear whether and how R&R can be achieved. Often, practical obstacles - such as psychological insecurity or licensing uncertainties (
Challenges for R&R during Data Collection
Creating new data can sometimes be impossible. For instance, when a lawyer interprets a piece of legislation, reproducibility would – optimally – mean that novel pieces of legislation on the same topic are interpreted while using the same interpretation method or model by different investigators. However, the investigators cannot create a new piece of legislation (the legislator would have to do that), but are limited to reinterpreting the same piece as in the original investigation. However, in this setup replicability could mean that other investigators interpret the same piece and test if they arrive at the same conclusion as the original investigator, which, according to our definition above, would rather count as a reproduction attempt. The original investigator could also attempt to reinterpret the same piece and test if they arrive at the same conclusion as in their first attempt. Again, according to our definition above, we would rather construe this procedure as a reproduction attempt.
When a sociologist interviews people on a certain topic to generate new data for a study, replicability would – optimally – mean that additional interviewees are questioned on the same topic using the same questions and in the same setup, by different investigators. However, a number of possible challenges for replicability could arise: The interviewees may differ in certain characteristics from those originally questioned, because of differences in the sampling strategy (
Some argue that no such thing as a exact replication, i.e., precisely repeating a previous piece of scholarship, exists “because there are always differences between the original study and the replication [...] (like small differences in reagents or the execution of experimental protocols). As a consequence, repeating the methodology does not mean an exact replication, but rather the repetition of what is presumed to matter for obtaining the original result.” (
However, even if exact replication is not possible, close or direct replication (
Challenges for R&R during data interpretation
Further, even if new data was generated in a manner that resembled exactly that of the original investigation, this data must be interpreted. This process of interpreting the data can be more or less objective (
In a similar vein, comparing the results of a reproduction or replication attempt to the findings of the original investigation, and defining whether the attempt was successful in showing the same result, is subject to interpretation. Reproducibility means being able to retrace how the original finding was achieved. But what if reproduction attempts are only partly successful, or if reproduction teams disagree with the methodological decisions of the original author? Such ambiguities may pose a challenge to cumulative scientific efforts, as it is unclear if the original and the replication finding should be treated separately or combined into meta-analytic evidence (
Interpreting what the absence of R&R success means is not straightforward either. Failing to reproduce or replicate could mean that the original finding under scrutiny was not representative for a real effect. – but not necessarily so, because of the multitude of things that could stand in the way between R&R success (see discussion above). For empirical research, for instance, because of regressive shrinkage in larger samples and measurement uncertainties, the effect sizes (e.g., the difference between an intervention group and a control group) are often expected to be much smaller in replication attempts than they had been in the original studies (
Method
Recognizing the discipline-specific difference in how R&R are defined and addressed, we sought to obtain an overview of how recent scholarly work treated R&R. To so do, we drew on projects conducted within Wikimedia’s “Open Science Fellows Program” (Fellowship Freies Wissen, which we will refer to as "Wikimedia Fellowship"), an interdisciplinary, long-running funding scheme for projects contributing to open research practices in Germany, Switzerland and Austria (
Twelve of these projects mentioned R&R explicitly in their project titles or descriptions, which implied that they either conducted a replication or tried to enhance R&R in their specific domain by, for instance, improving infrastructure (for a complete list, see Table
Overview of all Wikimedia Fellowship projects with focus on R&R. A complete list with annotations and more details on the projects can be retrieved from the OSF: https://osf.io/kqw3h/?view_only=296cae9077d146ee92d2372eed15d6c8.
| Project leader | Funding year | Project title | Academic discipline | Link |
| Arslan, R.C. | 2016/17 | Reproducible websites for everyone | Social Sciences | https://rb.gy/nkh65t |
| Breznau, N. | 2019/20 | Giving the Results of Crowdsourced Research Back to the Crowd. A Proposal to Make Data from 'The Crowdsourced Replication Initiative' Reliable, Transparent and Interactive | Social Sciences | https://rb.gy/ydez7u |
| Brohmer, H. | 2020/21 | Effects of Generic Masculine and Its Gender-fair Alternatives. A Multi-lab Study | Social Sciences | |
| Figueiredo, L. | 2020/21 | Computational notebooks as a tool for producitivty, transparency, and reproducibility | Life Sciences | https://rb.gy/jkv1zp |
| Hoffman, F.Z. | 2017/18 | Code, Data and Reproducibility – Open Computational Research | Engineering | https://rb.gy/hjaxg7 |
| Höchenberger, R. | 2017/18 | Quick estimation of taste sensitivity | Life Sciences | https://rb.gy/ysbjlx |
| Lasser, J. | 2019/20 | Executable papers: Tools for more reproducibility and transparency in the natural sciences | Natural Sciences | |
| Oertel, C. | 2020/21 | Acceleration of quality in the humanities – chances of open source implementation in research and training | Humanities | https://rb.gy/arpqf2 |
| Pethig, F. | 2020/21 | Data Version Control: Best Practice for Reproducible, Shareable Science? | Social Sciences | https://rb.gy/ihzetc |
| Rahal, R.-M. | 2018/19 | Reproducible practices make open and transparent research: An online course | Social Sciences | https://rb.gy/jeppln |
| Stutz, H. | 2017/18 | The Galss Tool – from development, to use, to the data set |
Engineering, Natural Sciences |
https://rb.gy/bi7lxf |
| Truan, N. | 2020/21 | Digital data – mine, yours, ours? Linguistic resources about digital communication as Open Data and Open Educational Resources for (higher) education | Humanities | https://rb.gy/trir4h |
For each of of these 12 projects, we contacted the person who received funding through the fellowship, asking for project-specific publications or deliverables. Where available, these publications were analyzed here, and supplemented using each project’s documentation on dedicated Wikiversity pages required by the funder.
For each of the projects, one of the present authors read the existing documentation, created a short summary, and coded basic project characteristics. The dataset with our codings has been provided as a supplement to this publication. Specifically, we coded the primary research area (humanities, engineering, life science, natural sciences, or social sciences), whether the projects produced infrastructure to advance R&R, and whether they tested R&R empirically. Following this initial assessment, we defined three broad categories of projects focusing on similar aspects of R&R:
- opening research processes by providing infrastructure,
- improving methods and data, standardizing knowledge, and
- making knowledge accessible through education and science communication.
Finally, we synthesized from the project materials how R&R were defined or conceptualized therein; and which challenges for R&R were mentioned.
Categorizing the Projects
As described previously, we derived three broad categories to organize the projects along their contributions to R&R. In the following, we will briefly introduce the three categories along with the projects. An overview of the projects is presented in Table
Opening Research Processes by Providing Infrastructure
The four projects in this category aimed at providing guidance and practical solutions to the challenge of reproducing data and analyses of research projects within fields where large amounts of data and sophisticated (pre-)processing are common. These projects were motivated by the fact that, for example, code may not be easily linked to the output reported in the paper (especially after some time has passed), or computational environments lacked certain dependencies (i.e., software libraries) that were used in the original analyses. In the following, we will briefly summarize each project.
Felix Hoffmann’s project “Code, Data and Reproducibility - Open Computational Research” was designed to facilitate research publications in accordance with three important criteria:
- documentation of data and code,
- documentation of software libraries used, and
- provisioning of a computational environment.
The outcome of this project is a hands-on guide to combining Docker and Sumatra to achieve the aforementioned goals. Future work points to the application of this practical approach to Hoffman’s own research on computational neuroscience.
Ludmilla Figueiredo’s project “Computational Notebooks as a Tool for Productivity, Transparency, and Reproducibility” provides a starter-kit for computational notebooks so that calculations performed as part of a paper can be traced and understood by others (
Jana Lasser’s project “Executable papers: Werkzeug für mehr Reproduzierbarkeit und Transparenz in den Naturwissenschaften” (Executable papers: Tools for more reproducibility and transparency in the natural sciences) taps into a similar problem and develops an executable paper, i.e., “dynamic pieces of software that combine text, raw data, and the code for work” (
Hans Henning Stutz’ project “The Glass Tool - from its development to its usage and to research data” tackles the issue of widespread “dark data” in the field of geotechnical engineering stemming from unique tools that produce intransparent data. He develops an experimental device to determine soil structure and resistance, making his construction drawings and monitoring software openly available. This open-method approach may enable other researchers to build on his solution and improve it in the future.
Improving Methods and Data and Standardizing Knowledge
The four projects in this category have in common that previous work in their respective domains might have lacked scrutiny and best practices to draw general conclusions. Hence, these projects aim at improvements in terms of methods or data quality by ensuring that knowledge generated from new data will be standardized and more reliable.
Charlotte Oertel’s project “Acceleration of quality in the humanities” developed a case study of how flawed art-historical analysis may propagate and get reinforced through subsequent citations. As an attempt to bar such forward-propagation, the author developed and tested an approach she called “citation genealogy analysis” (
In his project on the “Effects of Generic Masculine and Its Gender-fair Alternatives”, Hilmar Brohmer*
Richard Höchenberger’s project “Quick estimation of taste sensitivity” collects data meant “to be of larger practical use for clinical diagnostics”. To this end, they aimed at data standardization in order to build a “norm database” based on “measurements of healthy participants, i.e. a large set of reference data.” In order to construct such a reference database, the project implemented a method that will enable researchers to collaboratively collect and share data, namely deploying software tools that allow “researchers from different institutions to work collaboratively very easily”. A publication is forthcoming, but was not available at the time of writing (
Florian Pethig’s*
Making Knowledge Accessible Through Education and Science Communication
Beside their main goal of making research more transparent for peers within the field (see
Ruben Arslan’s project “Reproducible websites for everyone” was special, as he faced the issue of making open-science practices compatible with ethical and legal standards: his project’s data contained sensitive information on Swedish men’s reproductive behavior and offspring over time. As data sharing was not an option in this context, he worked on a solution to make the results available on a reproducible website, which he and his collaborators launched in 2017 (see
Nate Breznau’s project “Giving the Results of Crowdsourced Research Back to the Crowd” also made use of a reproducible website. Together with a team of many independent researchers, he analyzed the same data with the same underlying hypothesis: Does immigration undermine citizens’ support for social policies? The results differed a lot throughout the labs, depending on their analysis strategies. To make the results of this multi-lab project accessible to the public, Breznau created a reproducible website, which contained dynamic figures and graphs of the key findings.
Rima-Maria Rahal’s*
Naomi Truan’s project “Digitale Daten — meine, deine, unsere?” (Digital data – mine, yours, ours?) was designed as a didactic intervention within a research-based linguistics seminar on “Grammar in the Digital Age”. The author and a colleague assigned creative tasks in the course of two iterations of this class and surveyed their students, inter alia, on their willingness to publish academic posters in Open Access and getting taught through Open Educational Resources (OER). Their data show that 12 out of 15 student groups were willing to share their posters and were motivated by feeling included within a “community of practice” even outside the course (
Reproducibility and Replicability in the Selected Projects
Reproducibility
Especially in the quantitative scientific projects, reproducibility often means reusing the materials and data of a study and being able to recreate the results of the original study. In psychology and the social sciences, quantitative studies are made reproducible by a transparent source code that is compatible with the data at hand and produces the same statistical results as those reported in the original manuscript. Researchers in these disciplines frequently used programming languages, such as R (
By contrast, Arslan and Breznau aimed to address this problem in a somewhat different fashion: Arslan recognized that sharing data of his project brought about ethical issues (see section on challenges). As sharing methods and data was not possible, his reproducible website draws anonymized data and code from different repositories and presents the results in figures accompanied by textboxes, making them easily understandable. Moreover, Arslan provided a transparent workflow, which partly constitutes an infrastructure for other researchers to achieve such undertakings. Breznau and his collaborators have taken this idea one step further: First, they showed how several researchers achieved different results for a study, using the same data (hence, highlighting that results may differ if the original statistical code is not shared). Importantly, this multiverse of results was then also presented on a reproducible website, making it accessible for everyone. On this website, they not only presented the aggregated results, but also demonstrated how results change, based on decisions of individual labs. Taken together, both research projects included a dimension of accessibility for making a study reproducible for everyone, thereby communicating results effectively to outsiders.
In the context of qualitative scholarship and the humanities, reproducibility followed a similar reasoning, in that reproduction attempts retrace the path by which the original insight was achieved. This can be achieved by attempting to follow the logic described by the original investigators, for instance with regard to their arguments or interpretation of the data. As one example from our corpus, Oertel’s project presents a case study of an instance where misleading to erroneous interpretations became accepted wisdom because the discipline (in this case, art history) proceeds citation-by-citation, continually building on earlier work. With Oertel’s online tool, researchers should be able to trace citation lines from modern publications back through referenced sources. This approach, which the author describes as “citation genealogy analysis”, bears a ready resemblance to reproducibility as applied to humanities research.*
Replicability
In the quantitative sciences, replicability often means running a new experiment, which generates new data either using the same materials (e.g., instructions, hardware, software) as the original study or novel materials.*
In the realm of engineering, replicating previous study results might not be as crucial as in the more basic social-scientific research. Instead, the standardization of data output and results is important to achieve comparability. As a lot of engineering tools and devices produce “dark data”, which is data stemming from intransparent internal processes, Stutz wants to avoid dark data for future geotechnical engineering projects by providing construction drawings, code, and a comprehensive documentation for his soil structure tools. Hence, he provides an infrastructure for generating data transparently, which other researchers in the field can profit from in the future.
In the scope of qualitative scholarship and the humanities, replicability follows a similar reasoning, in that new data is generated to assess if, based on this new data, the original insights can again be obtained (
Education as a Prerequisite for R&R
Raising awareness for the issue of R&R is crucial - especially during undergraduate education - because this is when potential future researchers are exposed to scientific practices for the first time. As, for instance, in Rahal’s online courses, understanding the importance of replicability of a finding in new studies can enhance students’ critical reflection about individual studies. This critical reflection may be accompanied by emphasizing the importance of open-science practices in comparison to questionable research practices (QRPs), which many older publications may suffer from.
Likewise, the reproducibility of previous findings is equally important. For instance, taking openly available results from Breznau’s or Arslan’s project can be a valuable starting point for students in methods classes trying to reproduce other findings, where data and code are available. Thanks to available infrastructure and software, teaching can also involve handling online repositories (e.g., Zenodo, GitHub), version control (e.g., Git), and even reproducible scripts for semester papers or bachelor theses (e.g., via Jupyter Notebook).
Truan showed that such a systematic introduction to open science and R&R in student courses can be effective: not only do students learn that these practices are potentially important in their own future work, but they feel committed to these practices, as they want to demonstrate them to fellow researchers in their community, planting the seed for a cultural change (
Contributions to Reproducibility and Replicability: A Synthesis
As illustrated in Fig.
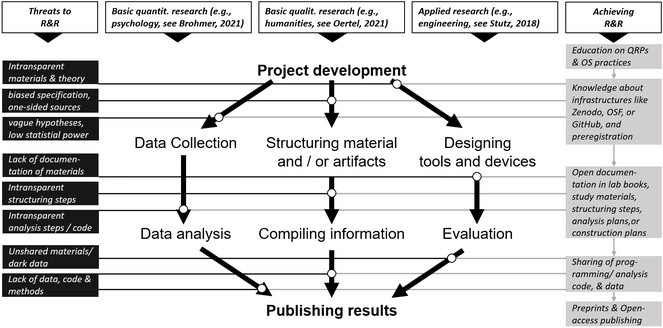
Threats to R&R and how to achieve it in three research domains. Note that horizontal lines connect different research steps (marked by circles on arrows) with boxes (“threats” and “achieving”) for R&R; light boxes are interconnected because R&R is an incremental process; domains are prototypical only and can overlap with other domains in reality. R&R = reproducibility and replicability; QRPs = questionable research practices; OS = open science.
Many of the Wikimedia Fellowship projects recognized and served a need for efforts to reproduce and replicate, either due to statistical-methodological problems in their field or due to limited comparability of research output more generally. Such problems include underpowered tests, decreasing the likelihood that statistically significant results show true effects (
Applied research and egineering might face issues that are different from the questionable research practices known from basic research. Rather, these problems concern intransparency and the subsequent lack of standardization of methods (see the project by Hans Henning Stutz). This is mainly because the development of tools and devices is done by individual researchers or small groups. They may be reluctant to share details about their materials and devices because they perceive their materials as intellectual property and do not see direct benefits in sharing them. Here, too, awareness has to rise that sharing of methods, codes, and construction plans has beneficial effects for the whole field. In the best case, engineers can exchange their knowledge, as it stems from similar software and tools, which increases comparability, but also the chance for collaborative endeavors across countries.
In the humanities, contributions to R&R focus mainly on increasing the digital availability of well-curated collections of artifacts: since humanities research relies on samples of intellectual production to be interpreted, contextualized, and compared, researchers used to elicit data by visiting archives or going on field trips by themselves. This often produces highly idiosyncratic notes that were never released except through the filtered form of published interpretations. This traditional approach faces increasing competition from digital research tools: As libraries and archives digitize their holdings, field trips are less relevant, while materials are accessible to and shared with greater numbers of researchers for mutual scrutiny, thus presumably increasing the reliability of interpretations derived from them.
Conclusion
Overall, our analysis shows that R&R is relevant across scientific disciplines and cultures, be it in the humanities, engineering, life science, natural sciences, or social sciences. Projects dedicated to advancing R&R took demonstrably different approaches, varying from enhancing step-by-step reproducibility through code-based transparency to tracing the origin of an argument through publication lines.
A majority of the 12 Wikimedia Fellowship projects assessed in detail here stem from social sciences and psychology, which closely mirrors recent developments in this research area (see
Notable differences were at which stages of the research process R&R becomes most relevant: whereas in basic research transparency remains relevant from the planning phase of a study to its publication and to its replication, in applied research the main focus may lie on the transparency of methods, as its goal may not be a reproducible and reproducible study, but a comparable methodology. In the humanities, a main focus may be to achieve an objective and reliable interpretation of materials and artifacts and to share how one came to this interpretation.
Despite their marked differences, the cross-disciplinary projects reviewed here shared the goal of improving research practices through R&R. Our findings therefore illustrate that R&R recipes require adjustments to fulfill the needs of the respective fields and research traditions. As chefs adjust recipes to their tastes in the kitchen, researchers may need to adjust how they think of and work with R&R against the background of their disciplines. If these specific needs are addressed appropriately, we are optimistic that an open research culture, which holds R&R at its core, may lie ahead in the not-so-distant future.
Acknowledgements
We thank Lilli Wagner and Berit Heling for their help with formatting this manuscript.
The publication of this article was kindly supported by RIO. We would like to thank RIO and Wikimedia Deutschland for enabling this collection.
Author contributions
During data elicitation, each author reviewed, coded, and described three out of the twelve projects that form the basis of our analysis. The other coauthors subsequently reviewed and revised these parts. The remainder of the text was written collaboratively in iterative revisions.
Conflicts of interest
The authors Brohmer, Pethig, and Rahal were also the principal investigators in projects analyzed in this paper. We are not aware of other potential conflicts.
References
- Normative dissonance in science: Results from a national survey of U.S. scientists.Journal of Empirical Research on Human Research Ethics2(4):3‑14. https://doi.org/10.1525/jer.2007.2.4.3
- What makes a replication successful? An investigation of frequentist and Bayesian criteria to assess replication success.Ludwig Maximilian University of Munichhttps://doi.org/10.5282/ubm/epub.77434
- Arqus openness position paper. https://doi.org/10.5281/zenodo.588190
- Paternal age effects on offspring fitness in four populations. https://rubenarslan.github.io/paternal_age_fitness/0_krmh_massage.html#authors-acknowledgements. Accessed on: 2022-5-24.
- Paternal age and offspring fitness: Online supplementary website (v2.0.1). https://doi.org/10.5281/zenodo.838961
- 1,500 scientists lift the lid on reproducibility.Nature News533:452‑454. https://doi.org/10.1038/533452a
- Raise standards for preclinical cancer research.Nature483:531‑533. https://doi.org/10.1038/483531a
- Wikimedia Fellow-Programm Freies Wissen 2016 - 2021.ZenodoURL: https://zenodo.org/record/5788379
- The replication recipe: What makes for a convincing replication?Journal of Experimental Social Psychology50:217‑224. https://doi.org/10.1016/j.jesp.2013.10.005
- Power failure: Why small sample size undermines the reliability of neuroscience.Nature Reviews Neuroscience14(5):365‑376. https://doi.org/10.1038/nrn3475
- Evaluating replicability of laboratory experiments in economics.Science351(6280):1433‑1436. https://doi.org/10.1126/science.aaf0918
- The seven deadly sins of psychology: A manifesto for reforming the culture of scientific practice.Princeton University Presshttps://doi.org/10.2307/j.ctvc779w5
- Estimating the reproducibility of experimental philosophy.Review of Philosophy and Psychology12:9‑44. https://doi.org/10.1007/s13164-018-0400-9
- A Bayesian adaptive algorithm (QUEST) to estimate olfactory threshold in hyposmic patients.Journal of Sensory Studies.
- Scientific discovery in a model-centric framework: Reproducibility, innovation, and epistemic diversity.PLOS ONE14(5). https://doi.org/10.1371/journal.pone.0216125
- An open investigation of the reproducibility of cancer biology research.eLife3:e04333. https://doi.org/10.7554/eLife.04333
- Why replication is overrated.Philosophy of science86(5):895‑905. https://doi.org/10.1086/705451
- The regression trap and other pitfalls of replication science-Illustrated by the report of the Open Science Collaboration.Basic and Applied Social Psychology40(3):115‑124. https://doi.org/10.1080/01973533.2017.1421953
- A simple kit to use computational notebooks for more openness, reproducibility, and productivity in research.PLOS Computational Biology18(9):1010356. https://doi.org/10.1371/journal.pcbi.1010356
- Comment on “Estimating the reproducibility of psychological science.".Science351(6277):1037. https://doi.org/10.1126/science.aad7243
- What does research reproducibility mean?Science Translational Medicine8(341):341ps12‑341ps12. https://doi.org/10.1126/scitranslmed.aaf5027
- A general theory of objectivity: Contributions from the reformational philosophy tradition.Foundations of Science1‑15. https://doi.org/10.1007/s10699-021-09809-x
- Studies in the logic of explanation.Philosophy of Science15(2):135‑175. https://doi.org/10.1086/286983
- Maximal specificity and lawlikeness in probabilistic explanation.Philosophy of Science35(2):116‑133. https://doi.org/10.1086/288197
- Association between contextual dependence and replicability in psychology may be spurious.Proceedings of the National Academy of Sciences of the United States of America113(34):E4933‑E4934. https://doi.org/10.1073/pnas.1608676113
- Why most published research findings are false.PLoS medicine2(8):e124. https://doi.org/10.1371/journal.pmed.0020124
- Measuring the prevalence of questionable research practices with incentives for truth telling.Psychological Science23(5):524‑532. https://doi.org/10.1177/0956797611430953
- Investigating variation in replicability.Social psychology45(3):142‑152. https://doi.org/10.1027/1864-9335/a000178
- Creating an executable paper is a journey through Open Science.Communication Physics3(143):1‑5. https://doi.org/10.1038/s42005-020-00403-4
- Open Science and Epistemic Diversity: Friends or Foes?Philosophy of Science1‑21. https://doi.org/10.1017/psa.2022.45
- Challenges and suggestions for defining replication “success” when effects may be heterogeneous: Comment on Hedges & Schauer (2018).Psychological Methods24(5):571‑575. https://doi.org/10.1037/met0000223
- Is psychology suffering from a replication crisis? What does “failure to replicate” really mean?The American Psychologist70(6):487‑498. https://doi.org/10.1037/a0039400
- A note on science and democracy.Journal of Legal and Political Sociology1:115‑126. URL: https://heinonline.org/HOL/Contents?handle=hein.journals/jolegpo1
- How best to quantify replication success? A simulation study on the comparison of replication success metrics.Royal Society Open Science8(5):201697. https://doi.org/10.1098/rsos.201697
- Scientific utopia: II. Restructuring incentives and practices to promote truth over publishability.Perspectives on Psychological Science7(6):615‑631. https://doi.org/10.1177/1745691612459058
- Promoting an open research culture.Science348(6242):1422‑1425. https://doi.org/10.1126/science.aab2374
- Making sense of replications.ELife6:e23383. https://doi.org/10.7554/eLife.23383
- What is replication?PLOS Biology18(3):3000691. https://doi.org/10.1371/journal.pbio.3000691
- The best time to argue about what a replication means? Before you do it.Nature583(7817):518‑520. https://doi.org/10.1038/d41586-020-02142-6
- Replicability, robustness, and reproducibility in psychological science.Annual Review of Psychology73(1):719‑748. https://doi.org/10.1146/annurev-psych-020821-114157
- Estimating the reproducibility of psychological science.Science349(6251):aac4716. https://doi.org/10.1126/science.aac4716
- Editors’ introduction to the special section on replicability in psychological science: A crisis of confidence?Perspectives on Psychological Science7(6):528‑530. https://doi.org/10.1177/1745691612465253
- What should researchers expect when they replicate studies? A statistical view of replicability in psychological science.Perspectives on Psychological Science: A Journal of the Association for Psychological Science11(4):539‑544. https://doi.org/10.1177/1745691616646366
- Replicability and replication in the humanities.Research Integrity and Peer Review4(1):2. https://doi.org/10.1186/s41073-018-0060-4
- Reproducibility vs. replicability: A brief history of a confused terminology.Frontiers in Neuroinformatics11https://doi.org/10.3389/fninf.2017.00076
- Open for Insight: An online course in experimentation.PsychArchives. https://doi.org/10.23668/psycharchives.4319
- R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.r-project.org/index.html
- Scientific objectivity. In:The Stanford Encyclopedia of Philosophy (Winter 2020).Metaphysics Research Lab, Stanford UniversityURL: https://plato.stanford.edu/archives/win2020/entries/scientific-objectivity/
- Promoting open science: A holistic approach to changing behaviour.Collabra: Psychology7(1):30137. https://doi.org/10.1525/collabra.30137
- What have we learned?eLife10:e75830. https://doi.org/10.7554/eLife.75830
- The file drawer problem and tolerance for null results.Psychological Bulletin86(3):638‑641. https://doi.org/10.1037/0033-2909.86.3.638
- False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant.Psychological Science22(11):1359‑1366. https://doi.org/10.1177/0956797611417632
- Norms of epistemic diversity.Episteme3:23‑36. https://doi.org/10.3366/epi.2006.3.1-2.23
- Name your favorite musician: Effects of masculine generics and of their alternatives in German.Journal of Language and Social Psychology20(4):464‑469. https://doi.org/10.1177/0261927X01020004004
- The alleged crisis and the illusion of exact replication.Perspectives on Psychological Science9(1):59‑71. https://doi.org/10.1177/1745691613514450
- How to increase data quality in the digital humanities? Two linked open data community approaches (preprint on file with authors).Elsevier
- Doing open science in a research-based seminar: Students' positioning towards openness in jigher education.HAL SHS Archives ouvertesURL: https://halshs.archives-ouvertes.fr/halshs-03395171
- Das eigene digitale Schreiben erforschen: Ein sprachwissenschaftliches Seminarkonzept zur Produktion, Analyse und Reflexion eigener digitaler Schreibpraktiken für angehende Deutschlehrkräfte.Herausforderung Lehrer*innenbildung - Zeitschrift zur Konzeption, Gestaltung und Diskussion (HLZ4(1):378‑397. https://doi.org/10.11576/hlz-4343
- UNESCO recommendation on open science (SC-PCB-SPP/2021/OS/UROS). URL: https://unesdoc.unesco.org/ark:/48223/pf0000379949.locale=en
- Contextual sensitivity in scientific reproducibility.Proceedings of the National Academy of Sciences of the United States of America113(23):6454‑6459. https://doi.org/10.1073/pnas.1521897113
- Python reference manual.Centrum voor Wiskunde en Informatica AmsterdamURL: https://www.python.org/
- Making replication mainstream.Behavioral and Brain Sciences41:e120. https://doi.org/10.1017/S0140525X17001972
Note that the project used the terms “reproducing” and “replicating” in exclusively negative connotation: It described art history as a field where flawed historical speculation gets carried forward by “continuous replication”, by being “still reproduced today”, even when newer evidence is available and past falsehoods have been corrected. This language construes reproduction as an ailment, so it may not appear intuitive to seek reproducibility as its cure.
Novel materials may be used either because the original materials are unavailable (e.g., because they have been lost or because they are not shared openly with the replication team), unsuitable (e.g., because they are written in a different language than that used by the replication team), or systematic variation is required (e.g., because boundary conditions should be tested; conceptual replication sensu (
This is a project by one of the co-authors.
In this context, we acknowledge that even the term "data" could mean very different things in different epistemic cultures and (within and across) academic fields (see