|
Research Ideas and Outcomes :
Conference Abstract
|
|
Corresponding author: Ronit Purian (purianro@tauex.tau.ac.il)
Received: 03 Oct 2022 | Published: 12 Oct 2022
© 2022 Ronit Purian, Natan Katz, Batya Feldman
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation:
Purian R, Katz N, Feldman B (2022) Explainability Using Bayesian Networks for Bias Detection: FAIRness with FDO. Research Ideas and Outcomes 8: e95953. https://doi.org/10.3897/rio.8.e95953
|
|
Abstract
In this paper we aim to provide an implementation of the FAIR Data Points (FDP) spec, that will apply our bias detection algorithm and automatically calculate a FAIRness score (FNS). FAIR metrics would be themselves represented as FDOs, and could be presented via a visual dashboard, and be machine accessible (
First we may discuss the context of this topic with respect to Deep Learning (DL) problems. Why are Bayesian Networks (BN, explained below) beneficial for such issues?
- Explainability – Obtaining a directed acyclic graph (DAG) from a BN training provides coherent information about independence variables in the data base. In a generic DL problem, features are functions of these variables. Thus, one can derive which variables are dominant in our system. When customers or business units are interested in the cause of a neural net outcome, this DAG structure can be both a source to provide importance and clarify the model.
- Dimension Reduction — BN provides the joint distribution of our variables and their associations. The latter may play a role in reducing the features that we induce to the DL engine: If we know that for random variables X,Y the conditional entropy of X in Y are low, we may omit X since Y provides its nearly entire information. We have, therefore, a tool that can statistically exclude redundant variables
- Tagging Behavior – This section can be less evident for those who work in domains such as vision or voice. In some frameworks, labeling can be an obscure task (to illustrate, consider a sentiment problem with many categories that may overlap). When we tag the data, we may rely on some features within the datasets and generate conditional probability. Training BN, when we initialize an empty DAG, may provide outcomes in which the target is a parent of other nodes. Observing several tested examples, these outcomes reflect these “taggers’ manners”. We can therefore use DAGs not merely for the purpose of model development in machine learning but mainly learning taggers policy and improve it if needed.
- The conjunction of DL and Casual inference — Causal Inference is a highly developed domain in data analytics. It offers tools to resolve questions that on the one hand, DL models commonly do not and, on the other hand, the real-world raises. There is a need to find a framework in which these tools will work in conjunction. Indeed, such frameworks already exist (e.g., GNN). But a mechanism that merges typical DL problems causality is less common. We believe that the flow, as described in this paper, is a good step in the direction of achieving benefits from this conjunction.
- Fairness and Bias – Bayesian networks, in their essence, are not a tool for bias detection but they reveal which of the columns (or which of the data items) is dominant and modify other variables. When we discuss noise and bias, we address these faults to the column and not to the model or to the entire data base. However, assume we have a set of tools to measure bias (
Purian et al. 2022 ). Bayesian networks can provide information about the prominence of these columns (as they are “cause” or “effect” in the data), thus allow us to assess the overall bias in the database.
What are Bayesian Networks?
The motivation for using Bayesian Networks (BN) is to learn the dependencies within a set of random variables. The networks themselves are directed acyclic graphs (DAG), which mimic the joint distribution of the random variables (e.g.,
Real-World Example
In this paper we present a way of using the DL engine tabular data, with the python package bnlearn. Since this project is commercial, the variable names were masked; thus, they will have meaningless names.
Constructing Our DAG
We begin by finding our optimal DAG.
import bnlearn as bn
DAG = bn.structure_learning.fit(dataframe)
We now have a DAG. It has a set of nodes and an adjacency matrix that can be found as follow:
print(DAG['adjmat'])
The outcome has this form Fig.

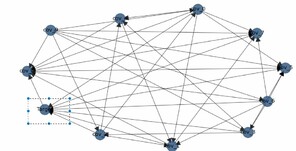
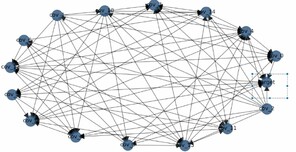
Where rows are sources (namely the direction of the arc is from the left column to the elements in the row) and columns are targets (i.e., the header of the column receives the arcs). When we begin drawing the obtained DAG, we get for one set of variables the following image: Fig.
We can see that the target node in the rectangle is a source for many nodes. We can see that it still points arrows itself to two nodes. We will discuss this in the discussion (i.e.,
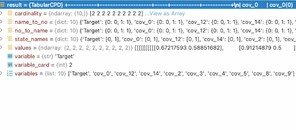
So, we know how to construct a DAG. Now we need to train its parameters. Code-wise we perform this as follows:
model_mle = bn.parameter_learning.fit(DAG, dataframe, methodtype='maximumlikelihood')
We can change ‘maximulikelihood’ with ‘bayes’ as described beyond. The outcome of this training is a set of factorized conditional distributions that reflect the DAG’s structure. It has this form for a given variable: Fig.
Discussion
In this paper we have presented some of the theoretical concepts of Bayesian Networks and the usage they provide in constructing an approximated DAG for a set of variables. In addition, we presented a real-world example of end to end DAG learning: Constructing it using BN, training its parameters using maximum likelihood estimation (MLE) methods, and performing and inference.
FAIR metrics, represented as FDOs, can also be visualised and monitored, taking care of data FAIRness.
Keywords
Bayesian networks (BN), causal inference, conditional entropy, deeg learning, dimension reduction, directed acyclic graph (DAG), neural networks, tagging behavior
Presenting author
Ronit Purian
Presented at
First International Conference on FAIR Digital Objects, poster
References
- The VODAN IN: support of a FAIR-based infrastructure for COVID-19.European Journal of Human Genetics28:724‑727. https://doi.org/10.1038/s41431-020-0635-7
- Finding Optimal Bayesian Network Given a Super-Structure.Journal of Machine Learning Research9(74):2251‑2286. URL: http://jmlr.org/papers/v9/perrier08a.html
- Unbiased AI.International Data Week (IDW)SciDataCon-IDW(AI & Reproducibility, Repeatability, and Replicability). URL: https://www.scidatacon.org/IDW-2022/sessions/467/paper/1098
- Precisely and Persistently Identifying and Citing Arbitrary Subsets of Dynamic Data.Harvard Data Science Review3(4). https://doi.org/10.1162/99608f92.be565013
- The FAIR Guiding Principles for scientific data management and stewardship.Scientific Data3:160018. https://doi.org/10.1038/sdata.2016.18