|
Research Ideas and Outcomes :
Research Idea
|
|
Corresponding author: Alberto Bucciero (alberto.bucciero@cnr.it)
Academic editor: Editorial Secretary
Received: 23 Aug 2022 | Accepted: 12 Sep 2022 | Published: 10 Mar 2023
© 2023 Alberto Bucciero, Emanuel Demetrescu, Bruno Fanini, Alessandra Chirivì, Francesco Taurino
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation:
Bucciero A, Demetrescu E, Fanini B, Chirivì A, Taurino F (2023) An approach to extend the metadata schema of Zenodo for Cultural Heritage datasets. Research Ideas and Outcomes 9: e93859. https://doi.org/10.3897/rio.9.e93859
|
|
Abstract
In this article, we present an approach designed to extend the metadata schema of the Zenodo data management platform to strengthen the FAIRness of the published dataset. We focus on a bottom-up approach starting from a series of datasets ranging from the 3D digitalisation of monuments and sites to the creation of reconstructive records (including the scientific documentation they are based on), to the implementation of digital storytelling and to the development of open source-based web-apps. We propose the simplest possible set of metadata to be included in the Zenodo platform with the possibility, for the community, to adopt and further develop/modify them. This article will describe in detail the formalisation and the digital formats adopted providing the related metadata templates developed within the projects.
Keywords
metadata, data FAIRness, FAIR, cultural heritage, data management, heritage science
Overview and background
The ability to publish, share and ensure long-lasting research results is one of the main goals of the policy known as "Data FAIRness"(
This situation is particularly evident in the field of Heritage Science (HS). Databases regarding the same cultural context are "stratified" —not integrated— over the years and formalised in heterogeneous ways, relying on non-standardised data ingestion and preservation strategies, based mainly on customised and non-generalisable data modelling solutions (metadata schema redundancies). Only in recent years has an increased focus on interoperability and the adoption of semantic knowledge networks laid the groundwork for standardisation that respects the multifaceted reality of the cultural record.
Objectives
OpenAire's effort has led to the establishment of Zenodo as a valuable platform for the management and long-lasting preservation of research data, including scientific datasets. Despite its ambition, the extreme descriptive poverty of the meta-information that can be instantiated does not allow for an optimal description of either such datasets. On the other hand, the scientific research process requires numerous steps, each characterised by specific methodologies, tools and data that are processed and that produce other output data in each single step of the sub-process. To keep track of the entire scientific process and, ultimately, to make this process FAIR, it is, therefore, essential to be able to fully describe the datasets used.
These considerations led us to identify a technical-scientific method that allows us to use Zenodo to extend its meta-descriptive capabilities, to store an additional set of information in the HS domain that can more efficiently identify and make searchable search results and all related datasets.
Implementation
One of the main limitations recognised in the Zenodo platform is the lack of ability to decorate data with appropriate metadata qualifying the specific application domain. Essentially, Zenodo almost exclusively supports a basic metadata scheme derived from Dublin Core (
In addition, the lack of support for extension towards customised metadata schemes is one of the main critical issues of Zenodo, especially in specific fields of applications, such as Cultural Heritage.
The first draft of a possible solution has been released on Zenodo (
- an operational methodology that guides the user step by step in publishing datasets, specifying how to add a set of domain metadata compared to the basic ones provided by default by the platform;
- a set of metadata specific to the Heritage Science domain that can fully qualify the dataset by declaring some salient features.
This contribution will add more theoretical and practical context describing new approaches to the publication of semantic-based datasets and to the publication of structured data, as well as the software and algorithms used to modify and transform the data flow from the sources to the final scientific dataset.
Finally, we will present the design of an architectural model (Fig.
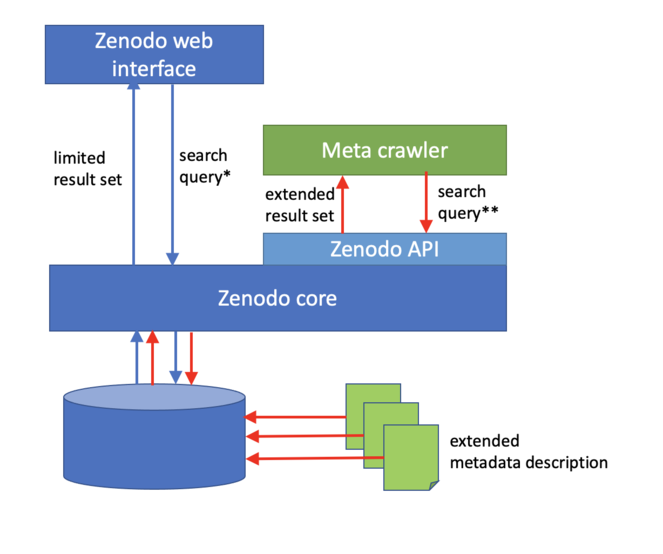
We propose to enrich the basic descriptive capability of Zenodo (based just on Dublin Core) by adding a "sister file" containing all the metadata needed to fully qualify the dataset. In this way, a search query can be executed by:
- searching into the native metadata provided directly by Zenodo (blue route in Fig.
1 ); - searching into the extended metadata description by calling the Zenodo API and obtaining the "sister file" corresponding to that specific dataset (red route in Fig.
1 ).
References
- Manuale operativo di metadatazione dei dataset per Zenodo nei Beni Culturali. https://doi.org/10.5281/zenodo.6138586
- FAIR Principles: Interpretations and Implementation Considerations.Data Intelligence2:10‑29. https://doi.org/10.1162/dint_r_00024
- Dublin Core Metadata Standard. http://www.oclc.org:5046/conferences/metadata/dublin_core_report.html
- The FAIR Guiding Principles for scientific data management and stewardship.Scientific Data3(1). https://doi.org/10.1038/sdata.2016.18