|
Research Ideas and Outcomes :
Review Article
|
|
Corresponding author: M.V. Eitzel (mveitzel@ucsc.edu)
Academic editor: Editorial Secretary
Received: 13 Jul 2021 | Accepted: 02 Sep 2021 | Published: 08 Sep 2021
© 2021 M.V. Eitzel
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation:
Eitzel M.V (2021) A modeler's manifesto: Synthesizing modeling best practices with social science frameworks to support critical approaches to data science. Research Ideas and Outcomes 7: e71553. https://doi.org/10.3897/rio.7.e71553
|
|
Abstract
In the face of the "crisis of reproducibility" and the rise of "big data" with its associated issues, modeling needs to be practiced more critically and less automatically. Many modelers are discussing better modeling practices, but to address questions about the transparency, equity, and relevance of modeling, we also need the theoretical grounding of social science and the tools of critical theory. I have therefore synthesized recent work by modelers on better practices for modeling with social science literature (especially feminist science and technology studies) to offer a "modeler’s manifesto": a set of applied practices and framings for critical modeling approaches. Broadly, these practices involve 1) giving greater context to scientific modeling through extended methods sections, appendices, and companion articles, clarifying quantitative and qualitative reasoning and process; 2) greater collaboration in scientific modeling via triangulation with different data sources, gaining feedback from interdisciplinary teams, and viewing uncertainty as openness and invitation for dialogue; and 3) directly engaging with justice and ethics by watching for and mitigating unequal power dynamics in projects, facing the impacts and implications of the work throughout the process rather than only afterwards, and seeking opportunities to collaborate directly with people impacted by the modeling.
Keywords
algorithmic injustice, big data, citizen science, community-based participatory research, community and citizen science, critical theory, critical data science, data biography, data justice, data science, decision support, epistemology, ethical, legal, and social implications, interdisciplinary, high variety big data, high volume big data, history of science, machine learning, mixed methods, participatory modeling, qualitative analysis, quantitative analysis, quantitative-qualitative analysis, reproducibility, reproducibility crisis, science and technology studies, science and justice, situated knowledge, triangulation
Introduction
Data science has the potential to work towards a more sustainable, more equitable world. However, whether this potential is realized depends on how our modeling practices move us towards or away from those goals. For example, methods from predictive advertising in industry are being enthusiastically applied to academic, governmental, and non-governmental contexts (
Modelers have created manifestos for better individual and collective practices (e.g.
The paper is organized as follows: I first review several technical and ethical concerns about working with high-volume and high-variety big data (and particularly issues with machine learning techniques). I then describe the methodology behind and research questions motivating this review. Finally, I place modeling literature in interdisciplinary conversation with feminist STS and related literatures, collecting framings and practices into my own modeler's manifesto. This interdisciplinary collection of practices is organized around three themes: 1) context (epistemic consistency, data biographies, and mixed-methods), 2) collaboration (triangulation, uncertainty as openness, interdisciplinary fluency), and 3) justice (power dynamics, impacts and implications in society, community-based modeling).
Technical Concerns with High-Volume Big Data
While there are definite advantages to incorporating large amounts of data into modeling, many statistical issues multiply for large datasets ("high-volume big data"), including collinearity, false positives, and significant but tiny effects. Collinearity refers to the situation when several variables which are themselves correlated are used to predict an outcome of interest, potentially giving a result that the group does predict that outcome, but one may not be able to tell which variable is really responsible. There is no way to remove collinearity, though efforts to work with it are long-standing (see
If one chooses to use hypothesis-testing methods, the approach of including many predictor variables also means a higher chance of having a "multiple testing" problem. Getting meaning from hypothesis-testing depends on the idea of controlling the rate of false positives (the alpha level or Type I error). This means that an individual statistical test might have a 5% chance of accidentally suggesting that something of interest is going on (when nothing is going on). There are ways to correct for this problem (e.g. "False Discovery Rate,"
There are many techniques for handling these issues, but my point is that more data is not automatically better (
Context Issues with High-Variety Big Data
Data collected over multiple decades by a large and constantly changing set of people raise issues of how to handle high-variety big data. This kind of big data is characterized more by the lack of control over its source than its quantity (
Unfortunately,
Accounting for measurement methods is also a part of using participatory citizen science data, another form of potentially high-variety big data which is currently growing in popularity. (Note that I use the term "citizen science" in the broadest possible sense, referring to participatory research of all kinds, e.g.
Limitations of and Justice Issues with Predictive Models
Faced with enormous quantities of data and many variables, many analysts turn to predictive accuracy as a metric to avoid some of the issues raised above regarding high-volume big data. Concerning oneself only with the model’s ability to predict known data can be a robust way to check models (
First, commonly-used predictive machine learning methods are notoriously opaque, though this can vary for the specific model in question. Many of them epitomize
Not only do black box models not help us understand the answers they give -- they can also be dangerous societal tools.
I have been especially critical of predictive, algorithmic models. It should be noted that there are efforts underway to audit these kinds of algorithms (e.g.
Data Resources for Review
The issues I have raised in the introduction led me to seek out discussions with colleagues in a wide range of social science disciplines, including anthropology, communications, environmental justice, feminist studies, geography, psychology, science and technology studies, and sociology. During 2015-2018, through one-on-one meetings, participation in group events, auditing courses, and joining reading groups, I compiled a bibliography of pieces that addressed my questions regarding "better" modeling that could mitigate or avoid some of the issues I'd encountered. In reading this material, I reflected on how these social science framings (especially those from feminist STS) could inform my own modeling practices. From 2017-2020, I thematically coded these reflections via an iterative writing process (
Below, I outline the questions behind the project and my methods for evaluating and validating the results.
Research Questions
The questions that drove my literature review and synthesis process were the following:
- How do we make self-consistent epistemic choices based on quantitative modeling results (i.e. understanding how the methods are designed to produce knowledge and evaluating how well we follow those methods)? How do we use both qualitative and quantitative information and reasoning to do so?
- What is an effective way to re-purpose existing data, and is the gain from using this data worth the effort it takes to properly model a variety of quirks in experimental design or obervation process?
- How can we use social science framings, and Science and Technology Studies in particular, in an applied way to work with issues of irreproducibility (the inability to confirm the results of published research) and declining trust by the public in scientists in general and modelers in particular?
- How can we create and use models, especially algorithmic and big data models, in a more just way (specifically, to ensure equitable benefit for those who are impacted by the models)?
- How are modelers already discussing and addressing these issues?
Evaluation/validation Process
Assembling the manifesto practices was a qualitative research process, therefore I followed best practices for assessing qualitative research in checking the credibility, consistency, and transferrability of the manifesto (
- I grounded the manifesto practices in literature from a variety of social sciences (in particular, triangulating between anthropology, geography, sociology, science and technology studies, and feminist studies). (This cross-checking establishes believability or credibility, as a qualitative version of internal validity.)
- I checked my practices with the published writings of other modelers who were discussing ways of making modeling better and more trustworthy. (Establishing logical consistency by checking with outside reasoning, as a qualitative version of reliability.)
- I cross-checked my thinking with others both in and out of my own personal network of modelers and social science scholars: both colleagues as well as editors and anonymous peer reviewers gave insightful comments on the practices and literature I had assembled. Both modeling and social science colleagues indicated they would use the manifesto in teaching their students, indicating good potential for transferrability (qualitative generalizability).
- I continued to read new literature suggested by colleagues until the practices had stabilized at the nine presented below; that is, new literature I encountered tended to fit in with one of the existing practices. This resembles saturation in qualitative sampling (similar to ensuring a large enough sample size in quantitative work).
As a tool for modelers to apply to their own practice, for those developing data science pedagogy, and as a conversation-starter, I believe the manifesto is relatively rigorous as per the above validation processes.
Discussion
I have already noted situations with big data and predictive algorithms where modeling involves hidden and not-so-hidden biases. Because both critical scholars and practicing modelers are aware that modeling and data science can be subjective and deeply entangled with justice issues, we need modeling practices and ways of thinking that enable us to articulate and address these aspects of modeling. In the sections that follow, I draw from a multi- and interdisciplinary range of literature to collect critical data science and modeling practices that could serve this need. The organizing themes of these practices draw from my engagement with feminist STS, so I begin by briefly reviewing important ideas from
One way to try to understand the world through a lens distorted by known and unknown biases is to use more than one kind of lens, noting how each may distort the picture. This strategy is a key component of "feminist objectivity," which is "about limited location and situated knowledge" (
This framing of each model as a partial picture of the world aligns with modelers' thinking as well, particularly the understanding that "all models are wrong, but some are useful" (
Below, I explore these ideas of models as partial knowledges further and outline nine proposed practices, merging my own observations as a practicing modeler with advice and thoughts from both modelers and social scientists from many different disciplines. I name the disciplines of the authors I cite in the manifesto practices (largely based on their affiliations), to give a sense of the breadth of the advice base. The practices are organized into a set of three themes: context, collaboration, and justice.
Theme 1: Contextualizing Modeling
In my pursuit of science and technology studies training and my examination of my own modeling experiences, it became clear to me that contextualizing modeling was a key practice, in a broad sense: both in from the perspective of feminist objectivity ("situating" models) and in the sense of detailing methods to improve reproducibility (research question 3). The practices I group under "context" help to allow for better use of high-variety data (research question 2), and also speak to the evaluation of technical considerations associated with high-volume big data (research question 1).
Practice 1a) Epistemic consistency: Know the epistemology that underlies methods and draw conclusions appropriately
A key context for quantitative modeling is the epistemological background of a method: what is the underlying reasoning for how we believe we can learn about the world from the method? In my experience, understanding this is surprisingly difficult when canned software (whether open-source or proprietary) makes it easy to apply methods without being familiar with the underlying assumptions. Fortunately, I have found abundant online resources and training courses regarding the underlying assumptions of models and have been able to ask computer science and statistics colleagues to explain the often impenetrable documentation and underlying assumptions accompanying canned procedures. In more deeply investigating the epistemological background of statistical methods I have used in my work, I found that the history of the methods is important. For example,
A final note on epistemic guidelines: once I felt confident in the epistemic underpinnings of a method, if the restrictions of a particular quantitative epistemology felt uncomfortable, I have investigated alternatives. Hypothesis testing uses a construction of "null" versus "alternative," and either of these terms could be interpreted negatively or dismissively, while model selection approaches (
Practice 1b) Data biographies: Report the details and learn the ethnography of modeling
Another way of conceptualizing "giving context to modeling" is to provide more detail on the experimental apparatus, broadly construed, as a "data biography." Feminist studies scholar
Acknowledging that modeling frequently does not proceed in a linear, logical fashion -- and that recording the reasons for various decision points may aid understanding of how the final result came about -- is recognized by both engineers, suggesting describing modeling "paths," (
Methods for writing such "data biographies" could include extending a methods section to describe more details of the work or creating appendices with additional detail. Some journals now offer or suggest venues to publish more detailed accounts of methods (for example, www.protocols.io). One could publish a companion paper which describes the contexts in which the model arose, how the people involved interacted, what each of their backgrounds and perspectives were. In order to write a data biography, one may need to keep a modeler’s notebook or journal to keep track of choices and the reasons for them (proposed by modelers
Several issues arise from this idea of a data biography. First, how does one know which details of a context to include as part of the "apparatus list" (raised by geographer
As a final note, I have sometimes been on the other side, trying to re-purpose data or conduct a meta-analysis when the original study does not provide enough detail to model the observation process. In these cases, I have found myself using qualitative research methods (often learning them inefficiently "on the job"), e.g. interviewing the researchers about their methods. I would have benefited from more formal training in ethnographic methods, either via interdisciplinary instruction on mixed methods, getting advice from colleagues with these skills, or directly collaborating with them, in order to more effectively obtain the needed information in an appropriate timeframe.
Practice 1c) Mixed-methods analysis: Frame modeling processes as including quantitative and qualitative components
There can be an element of qualitative data synthesis at work behind quantitative models, which can also be valuable context to acknowledge. Many modelers openly recognize that data can be quantitative or qualitative (
As I have reflected on how to define quantitative and qualitative analysis, I found that I iterate between both ways of thinking. As I searched for guidance on what distinguished quantitative from qualitative methodology and how to combine quantitative and qualitative data, I eventually concluded that the two are surprisingly commingled, even in existing modeling practice. I encountered many different definitions of "qualitative," and even having learned qualitative research methods, I see easy ways to flexibly apply quantitative assessments to qualitatively-generated data. Similarly, I can identify many points in a quantitative analysis which involve qualitative assessments. For example: looking at a graph of quantitative measurements and then proceeding based on a qualitative observation about the shape of the graph or the clustering of the points; integrating quantitative knowledge about many different sources upfront into a qualitative sense of what to expect from a model result or model performance indicator; or using qualitative arguments to explain quantitative results. And qualitative approaches to data collection can provide valuable insight into designing model structure or determining model parameters. In many ways, the distinction between qualitative and quantitative methods is less about theoretical differences and more about analytical cultural differences. I am an example of a quantitatively trained researcher who has since learned qualitative methods, and I find that the ability to choose between methods in either category -- and sometimes combine them -- lends richness and rigor to my analysis. And there may be cases where qualitative analysis is taken more seriously if the researcher can speak the language of quantitative analysis as well (e.g. anthropologist
Theme 2: Collaboration with Other Partial Knowledges
Giving modeling better context allows better perspective on why phenomena might appear a certain way through a given modeling process, but this way of seeing is still only a partial view of the object of interest. Feminist objectivity suggests that we must also find ways to bring a given model into dialogue with multiple other partial views or knowledges in order to get a more complete picture (as per Haraway's "Situated Knowledges"). The practices I group under "collaboration" address ways to implement this strategy. They can help in assessing the technical issues with high-volume big data and lay the groundwork for addressing the issues of algorithmic knowledge (research question 1); this set of practices also connects with issues of reproducibility (research question 3).
Practice 2a) Triangulation: Because no modeling technique is truly objective, seek ways to check models using other knowledge
All models are partial representations, so one way to get a more complete picture is to use "triangulation," a method used by social scientists to bring multiple different datasets or sources of knowledge to bear on the same question (see educational researchers
Bringing multiple knowledges together does not always result in consensus, however, and allowing for knowledges not to eliminate each other when they do not agree is critical: collaborative modeling should not erase difference (see geographers and interdisciplinary scholars
There are established methods for triangulation in the form of meta-analysis. One prominent example from health research is the Cochrane method for combining information from different studies (
Triangulation also has something to offer the reproducibility debate. As described in the Introduction, actually reproducing studies requires more than reading methods (from historians of science and statisticians
Practice 2b) Uncertainty as openness: Reframe uncertainty as an invitation for collaboration rather than failure
Multiple stories are another way to reframe modeling uncertainty, as well. Environmental scientists
Uncertainty could guide us towards what to investigate further (whether quantitatively or qualitatively). For example, sensitivity analysis in population viability models involves investigating which demographic parameters like growth or survival have the largest impact on overall population growth or decline. The results of the sensitivity analysis can therefore point to biological quantities that are important to know precisely in order to accurately assess population viability. If these parameters are not well known, the analysis helps direct research priorities towards better constraining them (see mathematical ecologist
Engaging multiple interested parties with an attitude of openness and a knowledge that we may not be able to resolve the uncertainty but must act anyway (the "post-normal" view) might be a way forward for some of difficult contemporary issues of global concern (see geographers and environmental scientists
Practice 2c) Interdisciplinary fluency: Be aware of epistemological, normative, and vocabulary differences in diverse collaborations
Seeking interdisciplinary training and experience is key in working on critical contemporary problems (potentially assisting with triangulation, according to epidemiologists
In learning interdisciplinary collaboration skills, practical experience is key, and explicit training can be invaluable (see interdisciplinary scholars
Interdisciplinary collaboration should also enable modelers to address ethical issues at all stages of a project, either by collaborating with ethicists (see biologist and statistician
As we collectively and mindfully re-imagine contemporary modeling practice, we need interdisciplinary teams of practicing modelers and critical scholars. We can strive to be patient with different timelines and create an environment of mutual respect and trust where collaborators are able to admit ignorance and ask questions. These practices can be fostered at multiple levels, by both institutions and individuals.
Theme 3: Engaging with justice implications of modeling processes
When facing the reality of collaboratively bringing together different kinds of knowledge, issues of justice -- especially whose knowledge counts -- quickly crop up. This phenomenon is especially apparent in issues of algorithmic injustice (see mathematician/economist
Practice 3a) Power dynamics: Watch for and work to mitigate unjust interactions in collaborations
The ways in which different collaborators' relative circumstances emphasize their knowledge production over others can be critical in the success or failure of research. Feminist studies scholar
For example, in writing and working on interdisciplinary grants and projects, collaborators from different disciplines do not necessarily receive equal financial (and other) benefits. Even within a discipline, the majority of the labor can often be pushed onto less senior, more vulnerable team members (e.g. graduate students and postdoctoral researchers). Ensuring that greater labor and responsibility comes with appropriate authority, compensation, and credit could help to mitigate this imbalance. Even in explicitly participatory research, many authors do not give authorship credit to the communities they engage with (see interdisciplinary scholars
Learning to look through different lenses and to perceive the impacts of power differentials between collaborators is not typically part of modelers' training, but modelers can learn to facilitate discussions of these issues with colleagues -- explicit facilitation training could be useful here. Even being aware of or receptive to hearing about problems can be an important first step, and documenting these issues in the data biography may also be appropriate. Modelers and their collaborators may need to experiment with ways to mitigate power imbalances, even potentially pushing back on institutional or structural barriers that constrain them, where possible.
Practice 3b) Impacts and implications: Engage with what the work does in the world
Modeling does not take place in a vacuum, and engaging with its justice implications should involve asking who will be harmed and who will benefit from models, or as political ecologists might put it, who are the "winners and losers?" (
Mixed-method qualitative ground-truthing of models along with open access to their assumptions and mechanisms can be key for being responsible for the models' impact; if they begin to do damage but people can audit them, the system can auto-correct (see mathematician and economist
Practice 3c) Community-based modeling: Find opportunities to collaborate directly with people who will be affected by modeling results
Where possible, modelers can work directly with the people who will be impacted by their results (though one challenge is identifying not just intended end-users of models, but others who will be impacted as well). Mathematician and economist
Collaborative modeling also engages people with the modeling process and products and invites the opportunity for more just modeling. This approach incorporates some of the concepts of Participatory Action Research (PAR), in which research is "generally not done on participants; it is done with participants" (educational scholars
While it may not be feasible to engage with users during all phases of modeling, making an effort to increase engagement where possible could be a way to improve modeling transparency and trustworthiness. Many modelers are encouraging working with model users (see mathematicians, geographers and environmental scientists
Conclusions
I set out to understand how I could improve my modeling, and ultimately found that modelers are already engaging with many of the issues I had discovered from my work and my training in science and technology studies (research question 5). I also found that there was solid theoretical support from a wide range of social sciences for the practices modelers were already proposing and implementing. My manifesto reflects this movement-in-progress and also the potential for further work, and is meant to grow and change and be elaborated on: There are many different types of modeling, and the issues raised in the introduction and throughout the manifesto practices may apply differently to simulations, mathematical models, statistical models, and machine-learning driven predictive models.
Future work should therefore involve investigating which practices apply to what kinds of modeling, and to which stages of modeling -- for example, project development and choice versus implementation, evaluation, and/or publication (I have made an initial attempt in Fig.
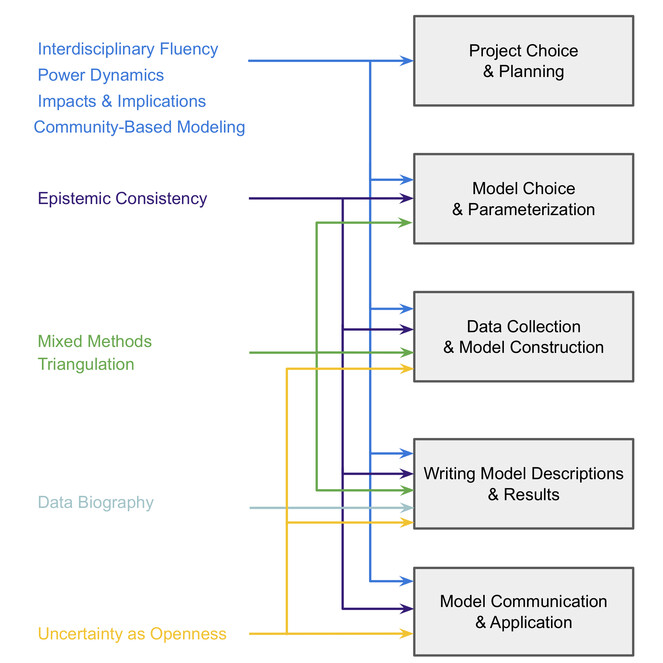
Workflow diagram for manifesto practices, showing which project stages may benefit from which practices. Interdisciplinary fluency, engaging with community-based modeling, and paying attention to power dynamics as well as impacts and implications are all important at all stages of modeling work. Epistemic consistency is important throughout model development (the three middle steps of model choice, construction, and description) and communication, while triangulation and mixed methods contribute largely to model development. The data biography is most important in the model description stage, though one may need to keep a journal and track details of the model development process in order to create the data biography. Treating uncertainty as openness is most important in model communication and application; however, this could feed back into iterative model development steps as well, or one could design models to aid in treating uncertainty as openness.
Modeler's manifestos have also pointed to the importance of institutional change as well as individual change (
Acknowledgements
This work relied on the discussions and literature recommendations of my colleagues, as well as their insightful comments on various drafts of the Manifesto. I thank a subset of them here: Martha Kenney, Jon Solera, Lizzy Hare, Jenny Reardon, Katherine Weatherford Darling, Perry de Valpine, Carl Boettiger, Andrew Mathews, Aaron Fisher, Ashley Buchanan, Eric Nost, Jenny Goldstein, Luke Bergmann, Justin Kitzes, K.B. Wilson, Jennifer Glaubius, Trevor Caughlin, and David O’Sullivan.
Grant title
SEES Fellows: Understanding the Dynamics of Resilience in a Social-Ecological System, Integrating Qualitative and Quantitative Information and Community-Based Action Research
Hosting institution
Science and Justice Research Center, University of California, Santa Cruz
Conflicts of interest
The author has no conflicts of interest to declare.
References
- The Toronto Declaration: Protecting the rights to equality and non-discrimination in machine learning systems.URL: https://www. accessnow. org/the-toronto-declaration-protecting-the-rights-to-equality-and-non-discrimination-in-machine-learning-systems/[February 16, 2019].
- My kingdom for a function: Modeling misadventures of the innumerate.Journal of Artificial Societies and Social Simulation6(3). URL: http://jasss.soc.surrey.ac.uk/6/3/8.html
- The end of theory: The data deluge makes the scientific method obsolete.Wired magazine16(7):16‑07.
- Finding your way in the interdisciplinary forest: notes on educating future conservation practitioners.Biodiversity and conservation23(14):3405‑3423. https://doi.org/10.1007/s10531-014-0818-z
- Opening the Black Box: Interpretable Machine Learning for Geneticists.Trends in Genetics36(6):442‑455. https://doi.org/10.1016/j.tig.2020.03.005
- Meeting the universe halfway: Quantum physics and the entanglement of matter and meaning.Duke University Presshttps://doi.org/10.2307/j.ctv12101zq
- Unsupervised by any other name: Hidden layers of knowledge production in artificial intelligence on social media.Big Data & Society6(1). https://doi.org/10.1177/2053951718819569
- The control of the false discovery rate in multiple testing under dependency.Annals of statistics1165‑1188.
- Toward speculative data:“Geographic information” for situated knowledges, vibrant matter, and relational spaces.Environment and Planning D: Society and Space34(6):971‑989. https://doi.org/10.1177/0263775816665118
- Model-Based Policymaking: A Framework to Promote Ethical “Good Practice” in Mathematical Modeling for Public Health Policymaking.Frontiers in Public Health5.
- Tackling the Algorithmic Control Crisis -the Technical, Legal, and Ethical Challenges of Research into Algorithmic Agents.Yale Journal of Law and Technology19(1). URL: https://digitalcommons.law.yale.edu/yjolt/vol19/iss1/3
- Building software, building community: lessons from the rOpenSci project.Journal of Open Research Software3(1).
- Empirical model-building and response surfaces.Wiley New York
- Critical questions for big data: Provocations for a cultural, technological, and scholarly phenomenon.Information, Communication & Society15(5):662‑679. https://doi.org/10.1080/1369118X.2012.678878
- Statistical modeling: The two cultures [Journal Article].Statistical Science16(3):199‑215. https://doi.org/10.1214/ss/1009213725
- Undoing the demos: Neoliberalism's stealth revolution.Mit Presshttps://doi.org/10.2307/j.ctt17kk9p8
- The science of citizen science: exploring barriers to use as a primary research tool.Biological Conservation208:113‑120. https://doi.org/10.1016/j.biocon.2016.05.014
- Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach.Springer
- Developing innovative services based on big data: The case of Go: SMART.Proceedings of the QUIS13 International Research Symposium on Service Excellence in Management. [ISBN978-91-7063-506-9].
- Matrix Population Models: Construction, Analysis, and Interpretation. 2nd edn Sinauer Associates.Inc., Sunderland, MA.
- Constructing grounded theory.Sage
- Situational analysis: Grounded theory after the postmodern turn.Sagehttps://doi.org/10.4135/9781412985833
- [Statistical Modeling: The Two Cultures]: Comment.Statistical Science16(3):216‑218.
- A multicountry assessment of tropical resource monitoring by local communities.BioScience64(3):236‑251. https://doi.org/10.1093/biosci/biu001
- How statistics lost their power–and why we should fear what comes next. URL: https://www.theguardian.com/politics/2017/jan/19/crisis-of-statistics-big-data- democracy
- The financial modelers' manifesto. https://doi.org/10.2139/ssrn.1324878
- Collinearity: a review of methods to deal with it and a simulation study evaluating their performance.Ecography36(1):27‑46. https://doi.org/10.1111/j.1600-0587.2012.07348.x
- Sources and amplifiers of climate change denial.Research Handbook on Communicating Climate Change49‑61. https://doi.org/10.4337/9781789900408.00013
- [Statistical modeling: The two cultures]: Comment.Statistical Science16(3):218‑219.
- Citizen science terminology matters: Exploring key terms.Citizen Science: Theory and Practice2(1):1‑20.
- Using mixed methods to construct and analyze a participatory agent-based model of a complex Zimbabwean agro-pastoral system.PLOS ONE15(8). https://doi.org/10.1371/journal.pone.0237638
- Indigenous climate adaptation sovereignty in a Zimbabwean agro-pastoral system: exploring definitions of sustainability success using a participatory agent-based model.Ecology and Society25(4). https://doi.org/10.5751/ES-11946-250413
- Assessing the Potential of Participatory Modeling for Decolonial Restoration of an Agro-Pastoral System in Rural Zimbabwe.Citizen Science: Theory and Practice6(1). https://doi.org/10.5334/cstp.339
- Autoethnography: An overview.Historical Social Research/Historische Sozialforschung36(4):273‑290.
- An overview of the system dynamics process for integrated modelling of socio-ecological systems: Lessons on good modelling practice from five case studies.Environmental Modelling & Software93:127‑145. https://doi.org/10.1016/j.envsoft.2017.03.001
- Companion modelling: a participatory approach to support sustainable development.Springer Science & Business Media
- The arrangement of field experiments.Journal of the Ministry of Agriculture of Great Britain33:503‑513.
- Participatory research in conservation and rural livelihoods: doing science together.John Wiley & Sons
- Epistemic injustice: Power and the ethics of knowing.Oxford University Presshttps://doi.org/10.1093/acprof:oso/9780198237907.001.0001
- Science for the post-normal age.Futures25(7):739‑755. https://doi.org/10.1016/0016-3287(93)90022-L
- The Statistical Crisis in Science.American Scientist102(6):460‑465. https://doi.org/10.1511/2014.111.460
- Writing as Method: Attunement, Resonance, and Rhythm.Affective Methodologieshttps://doi.org/10.1057/9781137483195.0018
- Cultural boundaries of science: Credibility on the line.University of Chicago Press
- Towards better modelling and decision support: Documenting model development, testing, and analysis using TRACE.Ecological Modelling280:129‑139. https://doi.org/10.1016/j.ecolmodel.2014.01.018
- Napa Valley historical ecology atlas: exploring a hidden landscape of transformation and resilience.Univ of California Presshttps://doi.org/10.1525/9780520951723
- Situated knowledges: The science question in feminism and the privilege of partial perspective.Feminist studies14(3):575‑599. https://doi.org/10.2307/3178066
- Shedding light on the dark data in the long tail of science.Library trends57(2):280‑299. https://doi.org/10.1353/lib.0.0036
- Cochrane Handbook for Systematic Reviews of Interventions.2nd Edition.John Wiley & Sons,Chichester (UK). https://doi.org/10.1002/9781119536604
- The strategy of building models of complex ecological systems.Systems analysis in ecology195‑214. https://doi.org/10.1016/B978-1-4832-3283-6.50014-5
- Ten iterative steps in development and evaluation of environmental models.Environmental Modelling & Software21(5):602‑614. https://doi.org/10.1016/j.envsoft.2006.01.004
- Technologies of humility.Nature450(7166):33‑33. https://doi.org/10.1038/450033a
- Counting, accounting, and accountability: Helen Verran’s relational empiricism.Social Studies of Science45(5):749‑771. https://doi.org/10.1177/0306312715607413
- The practice of reproducible research: Case studies and lessons from the data-intensive sciences.Univ of California Presshttps://doi.org/10.1525/9780520967779
- Climate change and transdisciplinary science: Problematizing the integration imperative.Environmental Science & Policy54:160‑167. https://doi.org/10.1016/j.envsci.2015.05.017
- A guide to eliciting and using expert knowledge in Bayesian ecological models.Ecology Letters13(7):900‑914. https://doi.org/10.1111/j.1461-0248.2010.01477.x
- Why pay attention to paths in the practice of environmental modelling?Environmental Modelling & Software92:74‑81. https://doi.org/10.1016/j.envsoft.2017.02.019
- Learning through computer model improvisations.Science, Technology, & Human Values38(5):678‑700. https://doi.org/10.1177/0162243913485450
- Priests and programmers: technologies of power in the engineered landscape of Bali.Princeton University Press
- Science in action: How to follow scientists and engineers through society.Harvard university press
- The future of environmental expertise.Annals of the Association of American Geographers105(2):244‑252. https://doi.org/10.1080/00045608.2014.988099
- Practicing interdisciplinarity.BioScience55(11):967‑975. https://doi.org/10.1641/0006-3568(2005)055[0967:PI]2.0.CO;2
- What difference does quantity make? On the epistemology of Big Data in biology.Big data & society1(1).
- Exploring rigour in autoethnographic research.International Journal of Social Research Methodology20(2):195‑207. https://doi.org/10.1080/13645579.2016.1140965
- Ethnographic Agency in a Data Driven World.Ethnographic Praxis in Industry Conference Proceedings2019(1):591‑604. https://doi.org/10.1111/1559-8918.2019.01316
- Seasonal components of avian population change: joint analysis of two large-scale monitoring programs.Ecology88(1):49‑55. https://doi.org/10.1890/0012-9658(2007)88[49:SCOAPC]2.0.CO;2
- Environmental justice in the age of big data: challenging toxic blind spots of voice, speed, and expertise.Environmental Sociology3(2):122‑133. https://doi.org/10.1080/23251042.2016.1220849
- Educational psychology: Constructing learning.Pearson Higher Education AU
- A checklist designed to aid consistency and reproducibility of GRADE assessments: development and pilot validation.Systematic Reviews3(1). https://doi.org/10.1186/2046-4053-3-82
- Competencies for the provision of comprehensive medication management services in an experiential learning project.PLOS ONE12(9). https://doi.org/10.1371/journal.pone.0185415
- Qualitative research: A guide to design and implementation.John Wiley & Sons
- Making an issue out of a standard: Storytelling practices in a scientific community.Science, Technology, & Human Values38(1):7‑43. https://doi.org/10.1177/0162243912437221
- Model histories: Narrative explanation in generative simulation modelling.Geoforum43(6):1025‑1034. https://doi.org/10.1016/j.geoforum.2012.06.017
- The body multiple: Ontology in medical practice.Duke University Press
- Undisciplining environmental justice research with visual storytelling.Geoforum102:267‑277. https://doi.org/10.1016/j.geoforum.2017.03.003
- HILDA - A Health Interaction Log Data Analysis Workflow to Aid Understanding of Usage Patterns and Behaviours.The 2nd Symposium on Social Interactions in Complex Intelligent Systems (SICIS) at Artificial Intelligence and Simulation of Behaviour Convention (AISB-2018). URL: https://pure.ulster.ac.uk/en/publications/hilda-a-health-interaction-log-data-analysis-workflow-to-aid-unde
- A manifesto for reproducible science.Nature Human Behaviour1(1):1‑9.
- Robust research needs many lines of evidence.Nature553:399‑401. https://doi.org/10.1038/d41586-018-01023-3
- Transforming self-driven learning using action research.Journal of Work-Applied Management10(1):4‑18. https://doi.org/10.1108/JWAM-10-2017-0029
- Interdisciplinary environmental studies: A primer.John Wiley & Sons
- Weapons of math destruction: How big data increases inequality and threatens democracy.Broadway Books
- Post-normal science in practice at the Netherlands Environmental Assessment Agency.Science, Technology, & Human Values36(3):362‑388. https://doi.org/10.1177/0162243910385797
- Big data is not about size: when data transform scholarship. In:Ouvrir, partager, réutiliser: Réflexion épistémologique sur les pratiques de recherche à partir des données numériques. [ISBN978-2-7351-2386-5]. https://doi.org/10.4000/books.editionsmsh.9103
- Trust in numbers: The pursuit of objectivity in science and public life.Princeton University Presshttps://doi.org/10.1515/9781400821617-004
- Closing the AI accountability gap.Proceedings of the 2020 Conference on Fairness, Accountability, and Transparencyhttps://doi.org/10.1145/3351095.3372873
- A Community of practice around peer review for long-term research software sustainability.Computing in Science & Engineering21(2):59‑65.
- On the emergence of science and justice.Science, Technology, & Human Values38(2):176‑200. https://doi.org/10.1177/0162243912473161
- Political ecology: A critical introduction.John Wiley & Sons
- When does HARKing hurt? Identifying when different types of undisclosed post hoc hypothesizing harm scientific progress.Review of General Psychology21(4):308‑320. https://doi.org/10.1037/gpr0000128
- Do p values lose their meaning in exploratory analyses? It depends how you define the familywise error rate.Review of General Psychology21(3):269‑275. https://doi.org/10.1037/gpr0000123
- The Users’ Judgements—The Stakeholder Approach to Simulation Validation. In:Computer Simulation Validation: Fundamental Concepts, Methodological Frameworks, and Philosophical Perspectives. [ISBN978-3-319-70766-2]. https://doi.org/10.1007/978-3-319-70766-2_17
- Can big data tame a “naughty” world?The Canadian Geographer/Le Géographe Canadien61(1):52‑63. https://doi.org/10.1111/cag.12338
- Where are the missing coauthors? Authorship practices in participatory research.Rural Sociology82(4):713‑746. https://doi.org/10.1111/ruso.12156
- Experiments in collaboration: interdisciplinary graduate education in science and justice.PLoS biology11(7).
- Uncertainty, complexity and concepts of good science in climate change modelling: are GCMs the best tools?Climatic change38(2):159‑205. https://doi.org/10.1023/A:1005310109968
-
In experts we trust?URL: https://www.bankofengland.co.uk/-/media/boe/files/speech/2017/in-experts-we-trust.pdf?la=en&hash=51801143BE9C2BAA60EF3F56F04D7A2E2C694952
- Trust in numbers.Journal of the Royal Statistical Society: Series A (Statistics in Society)180(4):948‑965. https://doi.org/10.1111/rssa.12302
- Before reproducibility must come preproducibility.Nature557(7706):613‑614. https://doi.org/10.1038/d41586-018-05256-0
- Implementing reproducible research.CRC Presshttps://doi.org/10.1201/b16868
- Action research.Sage publications
- Unruly complexity: Ecology, interpretation, engagement.University of Chicago Press
- Good science: The ethical choreography of stem cell research.MIT Presshttps://doi.org/10.7551/mitpress/8822.001.0001
- Science and an African logic.University of Chicago Press
- Modelling with stakeholders–next generation.Environmental Modelling & Software77:196‑220. https://doi.org/10.1016/j.envsoft.2015.11.016
- Indigenous Statistics.Routledgehttps://doi.org/10.4324/9781315426570
- Mechanisms for data quality and validation in citizen science.2011 IEEE Seventh International Conference on e-Science Workshops. https://doi.org/10.1109/eScienceW.2011.27
- Building and Auditing Fair Algorithms.Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparencyhttps://doi.org/10.1145/3442188.3445928
- Strategic positivism.The Professional Geographer61(3):310‑322. https://doi.org/10.1080/00330120902931952
Supplementary material
In this appendix, I explain in more detail how my background and values influenced my motivations and choices in creating the Modeler's Manifesto. I am putting into practice a part of the Manifesto itself, creating a description of the experimental apparatus (me) -- a part of the "data biography."