|
Research Ideas and Outcomes :
Project Report
|
|
Corresponding author: Ted Habermann (ted.habermann@gmail.com)
Received: 11 May 2020 | Published: 17 Jun 2020
© 2020 Ted Habermann
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Habermann T (2020) Metadata 2020 Metadata Evaluation Projects. Research Ideas and Outcomes 6: e54176. https://doi.org/10.3897/rio.6.e54176
|
|
Abstract
Metadata 2020: a cross-community collaboration that advocates richer, connected, reusable, and open metadata for all research outputs to advance scholarly pursuits for the benefit of society. A group of volunteers working together trying to encourage and facilitate progress towards this challenging goal. Management guru Peter Druker famously said “If you can’t measure it, you can’t improve it”. With that in mind, several Metadata 2020 projects examined approaches to metadata evaluation and connections between evaluation and guidance. Accomplishing this progress across the broad expanse of the Metadata 2020 landscape requires connecting metadata dialects and community recommendations and analysis of multiple metadata corpora. This paper describes one framework for approaching that task and some potential examples.
Keywords
metadata evaluation, metadata2020, dialects, community recommendations
Metadata standards, concepts, dialects and recommendations
Metadata 2020 undertook several projects based on themes that emerged from discussions in multiple community groups. These projects were connected in many ways under the banner of metadata improvement. The connection between the projects Metadata Recommendation and Element Mappings (
Scientific communities that recognize the need for metadata typically address that need using one of several approaches: they either use a metadata standard proposed by a related community or organization, or they develop a community standard. In most cases, they also include a standard representation for the metadata. We refer to these representations as metadata dialects. These metadata dialects include concept names, definitions and associated structures. A concept is a general, dialect-independent term for describing a documentation entity, frequently translating into an element or attribute defined in XML or some other representation. Typically, the communities or organizations that develop these standards also develop a set of recommendations for metadata content. We refer to these as dialect recommendations, i.e. recommendations explicitly associated with a dialect and its creators.
The relationship between dialects and recommendations is illustrated in Fig.
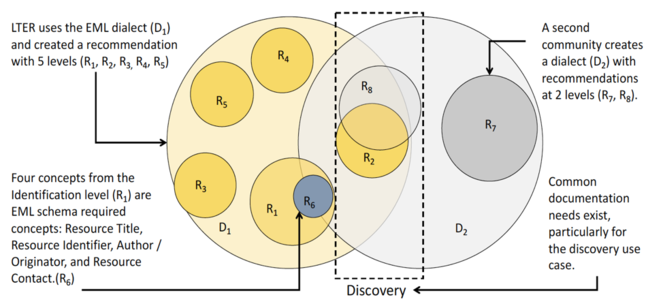
When another community, like FGDC, creates a second dialect (D2) with recommendations at two levels (R7 and R8), there is typically overlap between the dialects (most often for discovery content) and the recommendations, e.g. R2 and R8 in Fig.
Recommendations can also be created in a conceptual space independent of specific dialects, e.g the Catalog Service for the Web (
Approaches to metadata evaluation
Given the context of recommendations, dialects and communities, there are several different approaches that can be taken to metadata evaluation:
Record Curation: Do records conform to rules?
Individuals or teams (curators) select metadata records from a collection and evaluate those records against a set of rules. Some rules might be amenable to automatic checks (are links current and alive?), and some might require individual inspection (are abstracts understandable or correct?). This approach typically results in reports with suggested improvements for specific records.
Record/Collection Completeness: Are recommended concepts in the collection?
With a given recommendation or set of recommendations, a collection of records is checked for the existence of the elements that correspond to recommended concepts. In order to use this approach, the dialect and the mapping of the recommended concepts to the dialect must be known. This approach typically results in reports of completeness (%) of the collection with respect to each recommended concept.
Record Consistency: Is content consistent across the collection?
Records across a collection are examined to ensure that the content of elements that are expected to be the same are the same, e.g. names and identifiers of organizations are consistent, keywords are included from the correct shared vocabularies, units/other properties are reported consistently across parameters, etc. This approach typically results in reports of the most common content and variants for specific elements.
Dialect Utilization: What content is in the collection?
Dialects typically include content that is optional or not in any recommendations (see Fig.
Many of these approaches measure aspects of the “quality” of the metadata content and are often referred to as measures of metadata quality. In the big picture, understanding and evaluating metadata quality is highly dependent on the user community and is most effectively done using the question: Are the metadata sufficient to allow users to independently use, understand and trust these data. If the answer is yes, the metadata quality is high. Thus, testing overall metadata (or documentation) quality without user involvement is difficult, but community recommendations are designed, developed and evolved to serve as useful proxies for this user involvement.
Facilitating change
One goal of Metadata 2020 is to facilitate understanding and evolutionary change in the entire metadata community, i.e. researchers in many disciplines, data providers, funders, repositories, libraries, service providers, publishers and users. Fortunately we already have enthusiastic partners and champions in many of these communities. Even with this larger team, formulating and implementing a framework for change is difficult. The book "Switch: How to Change Things When Change is Hard " by
A related approach to facilitating change that might contribute to a useful framework is called “positive deviance” (
The projects
Hopefully these ideas will provide a common vocabulary for discussions of metadata evaluation and a framework for identifying tasks and getting them done. Of course, others may bring new ideas to the group that will augment or replace these.
Specifically, Metadata 2020 volunteers might aim initially at 1) identifying and understanding recommendations inside and outside of their communities, 2) connecting and harmonizing concepts across those recommendations and 3) connecting those concepts to important metadata dialects they work with. Once these connections are made, the completeness and consistency of actual metadata content can be evaluated.
In any case, the first task is identifying partners, understanding their potential contributions, and uniting those contributions into real-world work.
Project schematics
Pictures can help some people (i.e. visual learners) understand ideas and frame questions or improvements. I am one of those visual learners and I put together some pictures to describe two of the Metadata 2020 projects that I think are closely related.
Metadata Recommendations and Element Mappings (Project 2, Fig.
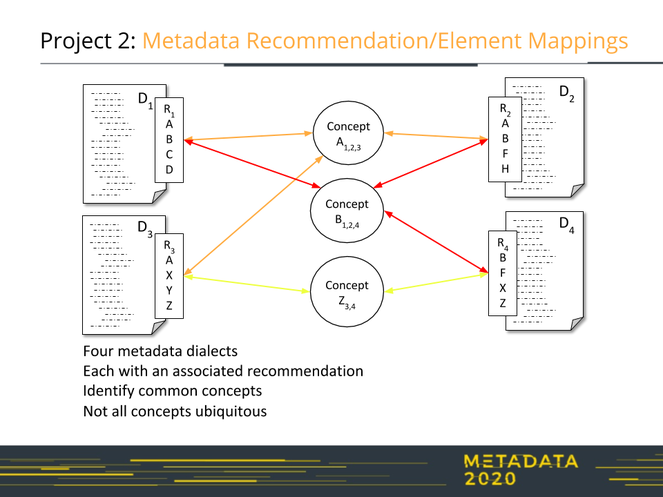
Identifying concepts that are shared across recommendations is the first part of Project 2. As each of these concepts has an implementation in each of the dialects, the mapping of concepts included in the recommendations leads fairly directly to a mapping between elements (the second phase of Project 2).
Once common concepts are identified and their mappings to implementations are known, we can evaluate their completeness in metadata collections for various dialects and in collections. This process is illustrated in Fig.
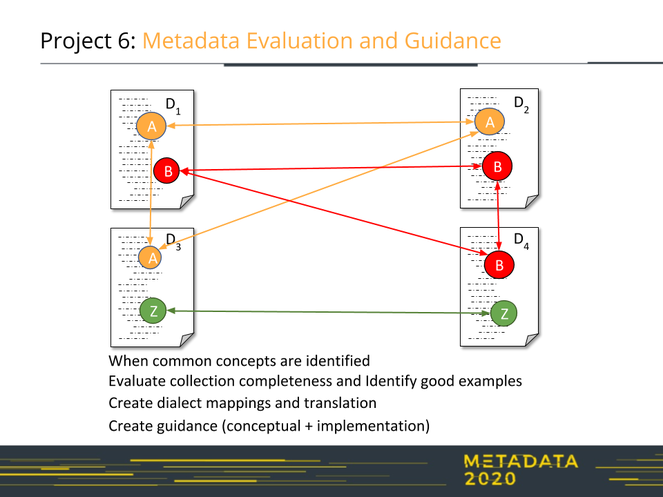
Note that some concepts may not occur in all dialects. Identifying these missing concepts provides important information for dialect developers and input on possible future directions.
This evaluation can involve some manual work - i.e. downloading a bunch of metadata and counting things up. This approach may work during the exploratory phase - trying to identify patterns and infer collection behaviors, but automated approaches that can be applied at scale are also helpful. See Metadata Evolution - CrossRef Participation Reports (
Evaluating collections is interesting for several reasons. First, it may help us identify common organizational behaviors and practices, to determine who does what and who else does similar (or different) things. My tendency is to focus on commonalities and things that work. Second, it helps us identify gaps in some collections that provide opportunities to improve while providing metrics that we might use to measure and demonstrate that improvement. Organizations that are trying to fill these gaps need consistent guidance (part two of this project) that includes use cases and good examples hopefully from within a single organization or from another that shares mission and goals. Finally, and most importantly, evaluations help us find those good examples that we can integrate into the guidance along with stories from the authors that describe why they did something well and how it helped them achieve a goal(s) for their users.
Conclusion
Metadata 2020 includes participants active in all phases of the scientific data life-cycle: researchers, metadata experts, librarians, publishers and users from many domains. They use many metadata dialects and support use cases across the life-cycle and domains. Developing common understanding across this broad group required awareness of differences in community vocabularies and connections between those vocabularies. Building on this understanding to evaluate metadata collections in multiple dialects and create guidance for practitioners are exciting future directions. Hopefully the ideas described here will be helpful in explaining what Metadata 2020 was thinking about and to help others find related stories to help us move forward.
Acknowledgements
The Metadata 2020 Core Team and the many volunteers that contributed to the project provided constant inspiration and great discussions throughout the project.
References
-
Content standard for digital geospatial metadata. https://www.fgdc.gov/metadata/csdgm-standard. Accessed on: 2020-4-22.
-
The Federal Geographic Data Committee. https://www.fgdc.gov/. Accessed on: 2020-4-22.
-
The influence of community recommendations on metadata completeness.Ecological Informatics43:38‑51. https://doi.org/10.1016/j.ecoinf.2017.09.005
-
Metadata evaluation and improvement. In: Earth Science Information PartnersMeeting Presentations.Earth Science Information Partners (ESIP),Washington D.C.,January 2014. https://doi.org/10.5281/zenodo.3750344
-
NO.MEN.CLA.TURE. http://www.metadata2020.org/blog/2017-09-21-nomenclature/. Accessed on: 2020-4-22.
-
Can we agree?http://www.metadata2020.org/blog/2018-02-02-can-we-agree/. Accessed on: 2020-4-22.
-
Metadata Evolution - CrossRef Participation Reports. https://www.tedhabermann.com/blog/2019/2/19/metadata-evolution-crossref-participation-reports. Accessed on: 2020-4-22.
-
Switch: How to chanfge things when change is hard.Crown Business[ISBN0385528752]
-
EML: Ecological Metadata Language. https://eml.ecoinformatics.org. Accessed on: 2020-4-22.
-
U.S. National Science Foundation LTER Network. https://lternet.edu/. Accessed on: 2020-4-22.
-
Project 2: Metadata Recommendations and Element Mappings. http://www.metadata2020.org/projects/mappings/. Accessed on: 2020-4-22.
-
Project 6: Metadata Evaluation and Guidance. http://www.metadata2020.org/projects/evaluation-guidance/. Accessed on: 2020-4-22.
-
Open Geospatial Consortium. https://www.ogc.org/. Accessed on: 2020-4-22.
-
Positive deviance. https://positivedeviance.org/. Accessed on: 2020-4-22.
-
Catalogue service for the Web. https://en.wikipedia.org/w/index.php?title=Catalogue_Service_for_the_Web&oldid=919480971. Accessed on: 2020-4-22.