|
Research Ideas and Outcomes : Research Presentation
|
|
Corresponding author: Viktor Senderov (datascience@pensoft.net)
Received: 23 Sep 2016 | Published: 23 Sep 2016
© 2016 Viktor Senderov, Teodor Georgiev, Lyubomir Penev.
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Senderov V, Georgiev T, Penev L (2016) Online direct import of specimen records into manuscripts and automatic creation of data papers from biological databases . Research Ideas and Outcomes 2: e10617. doi: 10.3897/rio.2.e10617
|

|
Abstract
Background
This is a Research Presentation paper, one of the novel article formats developed for the Research Ideas and Outcomes (RIO) journal and aimed at representing brief research outcomes. In this paper we publish and discuss our webinar presentation for the Integrated Digitized Biocollections (iDigBio) audience on two novel publishing workflows for biodiversity data: (1) automatic import of specimen records into manuscripts, and (2) automatic generation of data paper manuscripts from Ecological Metadata Language (EML) metadata.
New information
Information on occurrences of species and information on the specimens that are evidence for these occurrences (specimen records) is stored in different biodiversity databases. These databases expose the information via public REST API's. We focused on the Global Biodiversity Information Facility (GBIF), Barcode of Life Data Systems (BOLD), iDigBio, and PlutoF, and utilized their API's to import occurrence or specimen records directly into a manuscript edited in the ARPHA Writing Tool (AWT).
Furthermore, major ecological and biological databases around the world provide information about their datasets in the form of EML. A workflow was developed for creating data paper manuscripts in AWT from EML files. Such files could be downloaded, for example, from GBIF, DataONE, or the Long-Term Ecological Research Network (LTER Network).
Keywords
biodiversity informatics, bioinformatics, semantic publishing, API, REST, iDigBio, Global Biodiversity Information Facility, GBIF, PlutoF, BOLD Systems, ecological informatics, Ecological Metadata Language, EML, Darwin Core, LTER Network, DataONE, DwC-SW, semantic web
Introduction
On 16 June 2016, V. Senderov and L. Penev held a webinar presenting two novel workflows developed at Pensoft Publishers, used in the Biodiversity Data Journal (BDJ), and soon to be used also in other Pensoft journals of relevance: (1) automatic import of occurrence or specimen records into manuscripts and (2) automatic generation of data paper manuscripts from Ecological Metadata Language (EML) metadata. The aim of the webinar was to familiarize the biodiversity community with these workflows and motivate the workflows from a scientific standpoint. The title of the webinar was "Online direct import of specimen records from iDigBio infrastructure into taxonomic manuscripts."
Integrated Digitized Biocollections (iDigBio) is the leading US-based aggregator of biocollections data. They hold regular webinars and workshops aimed at improving biodiversity informatics knowledge, which are attended by collection managers, scientists, and IT personnel. Thus, doing a presentation for iDigBio was an excellent way of making the research and tools-development efforts of Pensoft widely known and getting feedback from the community.
Our efforts, which are part of the larger PhD project of V. Senderov to build an Open Biodiversity Knowledge Management System (OBKMS) (
The concept of data papers as an important means for data mobilization was introduced to biodiversity science by
Using this workflow, it is now possible to generate a data paper manuscript in AWT from a file formatted in recent EML versions.
Presentation
A video recording of the presentation is available. More information can be found in the webinar information page. The slides of the presentation are attached as supplementary files and are deposited in Slideshare.
During the presentation we conducted a poll about the occupation of the attendees, the results of which are summarized in
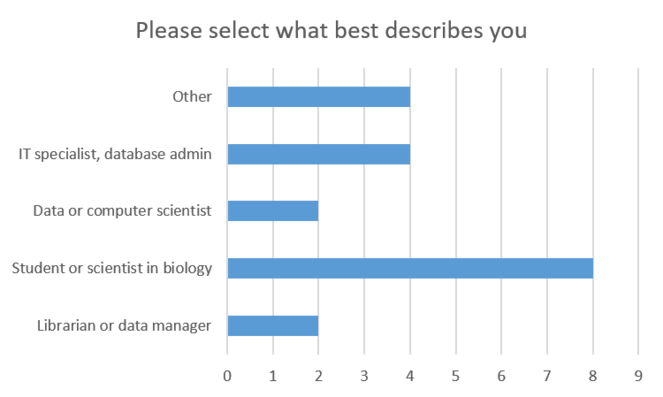
At the end of the presentation, very interesting questions were raised and discussed. For details, see the "Results and discussion" section of this paper.
Larry Page, Project Director at iDigBio, wrote: “This workflow has the potential to be a huge step forward in documenting use of collections data and enabling iDigBio and other aggregators to report that information back to the institutions providing the data."
Neil Cobb, a research professor at the Department of Biological Sciences at the Northern Arizona University, suggested that the methods, workflows and tools addressed during the presentation could provide a basis for a virtual student course in biodiversity informatics.
Methods
Both discussed workflows rely on three key standards: RESTful API's for the web (
RESTful is a software architecture style for the Web, derived from the dissertation of
- URI's have to be provided for different resources.
- HTTP verbs have to be used for different actions.
- HATEOAS (Hypermedia as the Engine of Application State) must be implemented. This is a way of saying that the client only needs to have a basic knowledge of hypermedia, in order to use the service.
On the other hand, Darwin Core (DwC) is a standard developed by the Biodiversity Information Standards (TDWG), also known as the Taxonomic Databases Working Group, to facilitate storage and exchange of biodiversity and biodiversity-related information. ARPHA and BDJ use the DwC terms to store taxonomic material citation data.
Finally, EML is an XML-based open-source metadata format developed by the community and the National Center for Ecological Analysis and Synthesis (NCEAS) and the Long Term Ecological Research Network (LTER,
Development of workflow 1: Automated specimen record import
There is some confusion about the terms occurrence record, specimen record, and material citation. A DwC Occurrence is defined as "an existence of an Organism at a particular place at a particular time." The term specimen record is a term that we use for cataloged specimens in a collection that are evidence for the occurrence. In DwC, the notion of a specimen is covered by MaterialSample, LivingSpecimen, PreservedSpecimen, and FossilSpecimen. The description of MaterialSample reads: "a physical result of a sampling (or sub-sampling) event. In biological collections, the material sample is typically collected, and either preserved or destructively processed." While there is a semantic difference between an occurrence record (DwC Occurrence) and a specimen record (DwC MaterialSample, LivingSpecimen, PreservedSpecimen, or FossilSpecimen), from the view point of pure syntax, they can be considered equivalent since both types of objects* are described by the same fields in our system grouped in the following major groups:
- Record-level information
- Event
- Identification
- Location
- Taxon
- Occurrence
- Geological context
Taxonomic practice dictates that authors cite the materials their analysis is based on in the treatment section of the taxonomic paper (
At the time when development of the workflow started, AWT already allowed imp ort of specimen records as material citations via manual interface and via spreadsheet (
In
In order to abstract and reuse source code we have created a general Occurrence class, which contains the code that is shared between all occurrences, and children classes GbifOccurrence, BoldOccurrence, IDigBioOccurrence, and PlutoFOccurrence, which contain the provider-specific code. The source code is written in PHP.
* Note: we are using the term objects here in the computer science sense of the word to denote generalized data structures.
Development of workflow 2: Automated data paper generation
Data papers are scholarly articles describing a dataset or a data package (
Data resources
The presentation this paper describes is available from Slideshare: www.slideshare.net/ViktorSenderov/online-direct-import-of-specimen-records-from-idigbio-infrastructure-into-taxonomic-manuscripts.
Results and discussion
Workflow 1: Automated specimen record import into manuscripts developed in the ARPHA Writing Tool
Implementation: It is now possible to directly import a specimen record as a material citation in an ARPHA Taxonomic Paper from GBIF, BOLD, iDigBio, and PlutoF (Slide 5, as well as

This fictionalized workflow presents the flow of information content of biodiversity specimens or biodiversity occurrences from the data portals GBIF, BOLD Systems, iDigBio, and PlutoF, through user-interface elements in AWT to textualized content in a Taxonomic Paper manuscript template intended for publication in the Biodiversity Data Journal.
- At one of the supported data portals (BOLD, GBIF, iDigBio, PlutoF), the author locates the specimen record he/she wants to import into the Materials section of a Taxon treatment (available in the Taxonomic Paper manuscript template).
- Depending on the portal, the user finds either the occurrence identfier of the specimen, or a database record identifier of the specimen record, and copies that into the respective upload field of the ARPHA system (
Fig. ).3 - After the user clicks on "Add," a progress bar is displayed, while the specimens are being uploaded as material citations.
- The new material citations are rendered in both human- and machine-readable DwC format in the Materials section of the respective Taxon treatment and can be further edited in AWT, or downloaded from there as a CSV file.
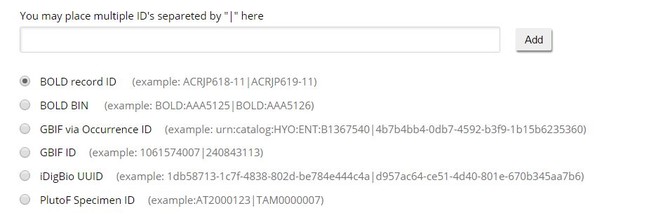
User interface of the ARPHA Writing Tool controlling the import of specimen records from external databases.
Discussion: The persistent unique identifiers (PID's) are a long-discussed problem in biodiversity informatics (
GBIF: Import from GBIF is possible both via a DwC occurrenceID, which is the unique identifier for the specimen/ occurrence, or via a GBIF ID, which is the record ID in GBIF's database. Thanks to its full compliance with DwC, it should be possible to track specimens imported from GBIF.
BOLD Systems: In the BOLD database, specimen records are assigned an identifier, which can look like `ACRJP619-11`. This identifier is the database identifier and is used for the import; it is not the identifier issued to the specimen stored in a given collection. However, some collection identifiers are returned by the API call and are stored in the material citation, for example, DwC catalogNumber and DwC institutionCode (see mappings in
A feature of BOLD Systems is that records are grouped into BIN's representing Operational Taxonomic Units (OTU's) based on a hierarchical/ graph-based clustering algorithm (
iDigBio: iDigBio provides its specimen records in a DwC-compatible format. Similar to GBIF, both a DwC occurrenceID, as well as DwC triplet information is returned by the system and stored in our XML making tracking of specimen citations easy.
PlutoF: Import from PlutoF is attained through the usage of a specimen ID (DwC catalogNumber), which is disambiguated to a PlutoF record ID by our system. If a specimen ID matches more than one record in the PlutoF system, multiple records are imported and the user has to delete the superfluous material citations. PlutoF does store a full DwC triplet while no DwC occurrenceID is available for the time being.
Ultimately, this workflow can serve as a curation filter for increasing the quality of specimen data via the scientific peer review process. By importing a specimen record via our workflow, the author of the paper vouches for the quality of the particular specimen record that he or she presumably has already checked against the physical specimen. Then a specimen that has been cited in an article can be marked with a star as a peer-reviewed specimen by the collection manager. Also, the completeness and correctness of the specimen record itself can be improved by comparing the material citation with the database record and synchronizing differing fields.
There is only one component currently missing from for this curation workflow: a query page that accepts a DwC occurrenceID or a DwC doublet/ triplet and returns all the information stored in the Pensoft database regarding material citations of this specimen. We envisage this functionality to be part of the OBKMS system.
Workflow 2: Automated data paper manuscript generation from EML metadata in the ARPHA Writing Tool
Implementation: We have created a workflow that allows authors to automatically create data paper manuscripts from the metadata stored in EML. The completeness of the manuscript created in such a way depends on the quality of the metadata; however, after generating such a manuscript, the authors can update, edit, and revise it as any other scientific manuscript in the AWT. The workflow has been thoroughly described in a blog post; concise stepwise instructions are available via ARPHA's Tips and tricks guidelines. In a nutshell, the process works as follows:
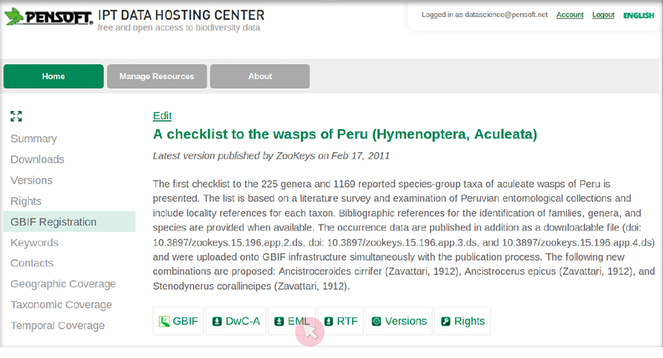
- The users of ARPHA need to save a dataset's metadata as an EML file (versions 2.1.1 and 2.1.0, support for other versions is being continually updated) from the website of the respective data provider (see
Fig. as an example using the GBIF's Integrated Publishing Toolkit (IPT)). Some leading data portals that provide such EML files are GBIF (EML download possible both from IPT and from the portal), DataONE, and the LTER Network.4 - Click on the "Start a manuscript" button in AWT and then select "Biodiversity Data Journal" and the "Data paper (Biosciences)" template (
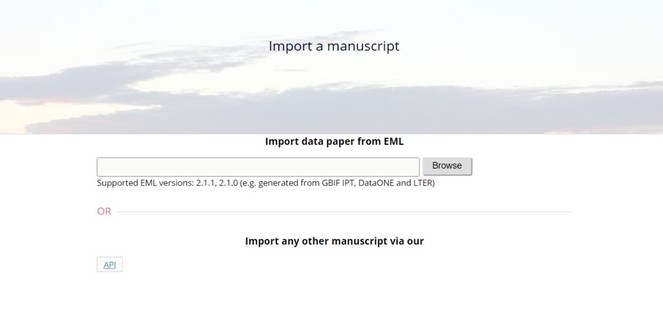
Fig. ).5 - Upload this file via the "Import a manuscript" function on the AWT interface (
Fig. ).6 - Continue with updating and editing and finally submit your manuscript inside AWT.
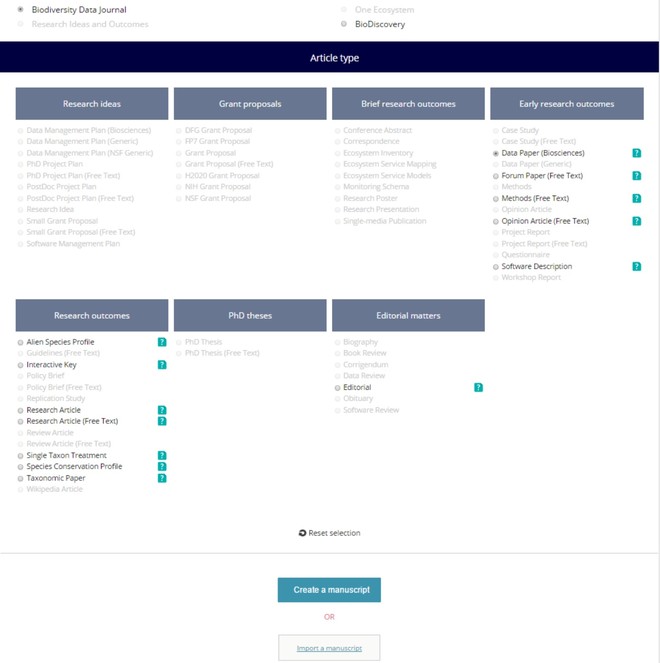
Selection of the journal and "Data Paper (Biosciences)" template in the ARPHA Writing Tool.
Discussion: In 2010, GBIF and Pensoft began investigating mainstream biodiversity data publishing in the form of "data papers." As a result this partnership pioneered a workflow between GBIF’s IPT and Pensoft’s journals, viz.: ZooKeys, MycoKeys, Phytokeys, Nature Conservation, and others. The rationale behind the project was to motivate authors to create proper metadata for their datasets to enable themselves and their peers to properly make use of the data. Our workflow gives authors the opportunity to convert their extended metadata descriptions into data paper manuscripts with very little extra effort. The workflow generates data paper manuscripts from the metadata descriptions in IPT automatically at the "click of a button." Manuscripts are created in Rich Text Format (RTF) format, edited and updated by the authors, and then submitted to a journal to undergo peer review and publication. The publication itself bears the citation details of the described dataset with its own DOI or other unique identifier. Ideally, after the data paper is published and a DOI is issued for it, it should be included in the data description at the repository where the data is stored. Within less than four years, a total of more than 100 data papers have been published in Pensoft's journals (examples:
The present paper describes the next technological step in the generation of data papers: direct import of an EML file via an API into a manuscript being written in AWT. A great advantage of the present workflow is that data paper manuscripts can be edited and peer-reviewed collaboratively in the authoring tool even before submission to the journal. These novel features provided by AWT and BDJ may potentially become a huge step forward in experts' engagement and mobilization to publish biodiversity data in a way that facilitates recording, credit, preservation, and re-use. Another benefit of this usage of EML data might be that in the future, more people wil provide more robust EML data files.
Feedback: The two workflows presented generated a lively discussion at the end of the presentation, which we summarize below:
- Are specimen records imported from GBIF and then slightly changed during the editorial process then deduplicated at GBIF? Answer: Unfortunately, no. At GBIF, deduplication only occurs for identical records.
- Are we leaving the identifiers from GBIF or iDigBio in the records? Answer: Yes. We have made the best effort to import specimen record identifiers. This has been discussed in the previous sections.
- How will the tool reduce the input time for constructing a manuscript? Answer: AWT reduces the time for creating a manuscript in two significant ways. First of all, the workflows avoid retyping of specimen records or metadata. Secondly, another time-saving feature is the elimination of copying errors. Creating of data paper manuscripts from EML saves, as a minimum, the effort of copy-pasting metadata and their arrangement in a manuscript.
- What are the major hurdles or challenges left in having this become a mainstream tool? How mature is the tool? Answer: We believe that the main hurdles in this becoming a main-stream tool are visibility and awareness of the tool by the community. As the stability of the software is already at a very good stage.
- Is it possible to track the usage of museum specimens for data aggregators? Answer: Yes, see question 2 and discussion in the present section.
- How do you go to the article page where collection managers can search for data published from their collections on the Pensoft website? Answer: We are working on the streamlining of this functionality. It will be part of the OBKMS. Currently, we markup collection codes against the Global Registry of Biodiversity Repositories (GRBio) vocabularies, and the reader can view the records from a particular collection by clicking on the collection code.
Acknowledgements
Thе authors are thankful to the whole Pensoft team, especially the software development unit, as well as the PlutoF, GBIF and iDigBio staff for the valuable support during the implementation of the project. Special thanks are due to Deborah Paul, Digitization and Workforce Training Specialist from iDigBio, for giving us the opportunity to present the workflow at the webinar as part of the iDigBio 2015 Data Management Working Group series. We also thank also our pre-submission reviewers for the valuable comments.
Funding program
The basic infrastructure for importing specimen records was partially supported by the FP7 funded project EU BON - Building the European Biodiversity Observation Network, grant agreement ENV30845. V. Senderov's PhD is financed through the EU Marie-Sklodovska-Curie Program Grant Agreement Nr. 642241.
Hosting institution
Pensoft Publishers, Bulgarian Academy of Sciences
Author contributions
The workflows were developed by:
- V. Senderov - main author and implementor of the XSLT and RESTfull API workflows.
- T. Georgiev - project manager, co-architect.
- L. Penev - scientific advisor, vision.
References
-
Darwin-SW: Darwin Core-based terms for expressing biodiversity data as RDF. http://www.semantic-web-journal.net/content/darwin-sw-darwin-core-based-terms-expressing-biodiversity-data-rdf-1. Accession date: 2016 7 14.
-
Journal Article Tag Suite Conference (JATS-Con) Proceedings 2010.Bethesda (MD): National Center for Biotechnology Information (US).6pp.
-
The data paper: a mechanism to incentivize data publishing in biodiversity science.BMC Bioinformatics12:S2. DOI: 10.1186/1471-2105-12-s15-s2
-
Cultural Change in Data Publishing Is Essential.BioScience63(6):419‑420. DOI: 10.1525/bio.2013.63.6.3
-
FORMIDABEL: The Belgian Ants Database.ZooKeys306:59‑70. DOI: 10.3897/zookeys.306.4898
-
Database of Vascular Plants of Canada (VASCAN): a community contributed taxonomic checklist of all vascular plants of Canada, Saint Pierre and Miquelon, and Greenland.PhytoKeys25:55‑67. DOI: 10.3897/phytokeys.25.3100
-
Maximizing the Value of Ecological Data with Structured Metadata: An Introduction to Ecological Metadata Language (EML) and Principles for Metadata Creation.Bulletin of the Ecological Society of America86(3):158‑168. DOI: 10.1890/0012-9623(2005)86[158:mtvoed]2.0.co;2
-
Architectural styles and the design of network-based software architectures. PhD Dissertation.Dept. of Information and Computer Science, University of California, Irvine.,180pp.
-
The Trouble with Triplets in Biodiversity Informatics: A Data-Driven Case against Current Identifier Practices.PLoS ONE9(12):e114069. DOI: 10.1371/journal.pone.0114069
-
Antarctic macrobenthic communities: A compilation of circumpolar information.Nature Conservation4:1‑13. DOI: 10.3897/natureconservation.4.4499
-
What is RESTful?ASP.NET MVC 4 and the Web API. URL: https://doi.org/10.1007/978-1-4302-4978-8_2 DOI: 10.1007/978-1-4302-4978-8_2
-
Meta-information concepts for ecological data management.Ecological Informatics1(1):3‑7. DOI: 10.1016/j.ecoinf.2005.08.004
-
Pensoft Data Publishing Policies and Guidelines for Biodiversity Data.Zenodo1:1. DOI: 10.5281/ZENODO.56660
-
Antarctic, Sub-Antarctic and cold temperate echinoid database.ZooKeys204:47‑52. DOI: 10.3897/zookeys.204.3134
-
A DNA-Based Registry for All Animal Species: The Barcode Index Number (BIN) System.PLoS ONE8(7):e66213. DOI: 10.1371/journal.pone.0066213
-
The Open Biodiversity Knowledge Management System in Scholarly Publishing.Research Ideas and Outcomes2:e7757. DOI: 10.3897/rio.2.e7757
-
A dataset from bottom trawl survey around Taiwan.ZooKeys198:103‑109. DOI: 10.3897/zookeys.198.3032
-
Vegetation and floristics of a lowland tropical rainforest in northeast Australia.Biodiversity Data Journal4:e7599. DOI: 10.3897/bdj.4.e7599
-
Darwin Core: An Evolving Community-Developed Biodiversity Data Standard.PLoS ONE7(1):e29715. DOI: 10.1371/journal.pone.0029715
Supplementary materials
A template for an occurrence or specimen record to be imported as a material citation.
Download file (157.00 kb)
This spreadsheet contains the information about the specimen API's of GBIF, BOLD Systems, iDigBio, and PlutoF. It lists the endpoints and the documentation URLs in the sheet named "APIs". In the sheet named "Mappings" it lists how to map the non-DwC compliant APIs (BOLD and PlutoF) to DwC-terms.
Download file (32.66 kb)
This archive contains XSLT transformations from EML v. 2.1.1 and v. 2.1.0 to Pensoft data paper format.
Download file (7.86 kb)