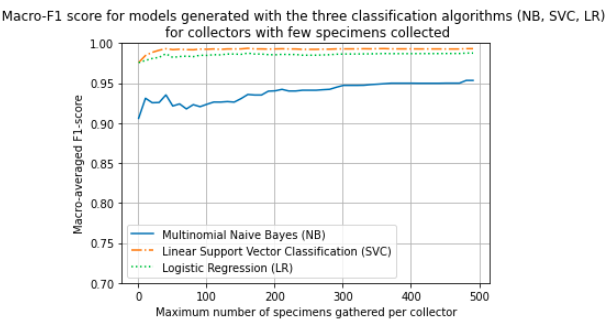
Results of applying the algorithms to text written by collectors with one collected sample up to 500 samples. The test was carried out to measure the impact of different collector's writing on the result and to verify if the resulting models were just trained to parse the writing of the prolific collectors. Training and test data were partitioned using the number of specimens gathered per collector. Specimen descriptions written by collectors with different amounts of gathering were selected for testing models, the rest of the samples were used to train the models.