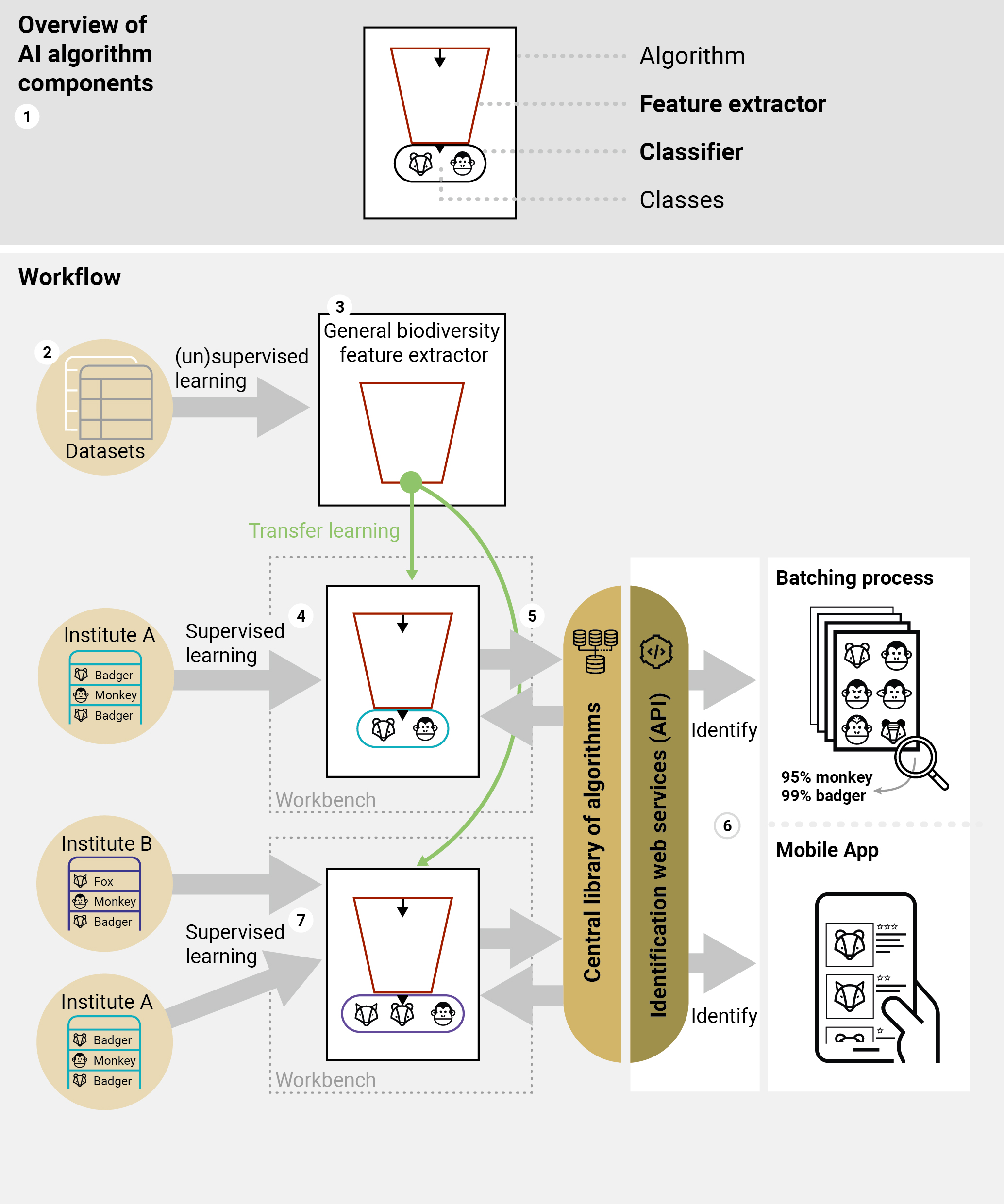
Sharing of taxonomic knowledge between institutes. (1) Each algorithm contains two basic components: the feature extractor and the classifier. (2) The Central Library of Datasets allows the user to browse through all available images of collection objects; (3) based on all available images, a regularly updated central feature extractor is created and published; (4) custom made algorithms can relatively easily be created by building a classifier based on a selection of taxa from the central library and combining this with the central feature extractor; (5) newly created algorithms together with their metadata (probability & information on content) are published through a web service in the Central Library of Algorithms (6) and can be used through the Identification web services (API) either for batch processing of images or through a mobile app. Models can be easily extended by other institutions by combining data sources (7).